TAPE Benchmark: Assessing Few-shot Russian Language Understanding
About
Paper
Toolkit
Leaderboard
Datasets
Baselines
Model Evaluation
For a more detailed evaluation results of the models see below:
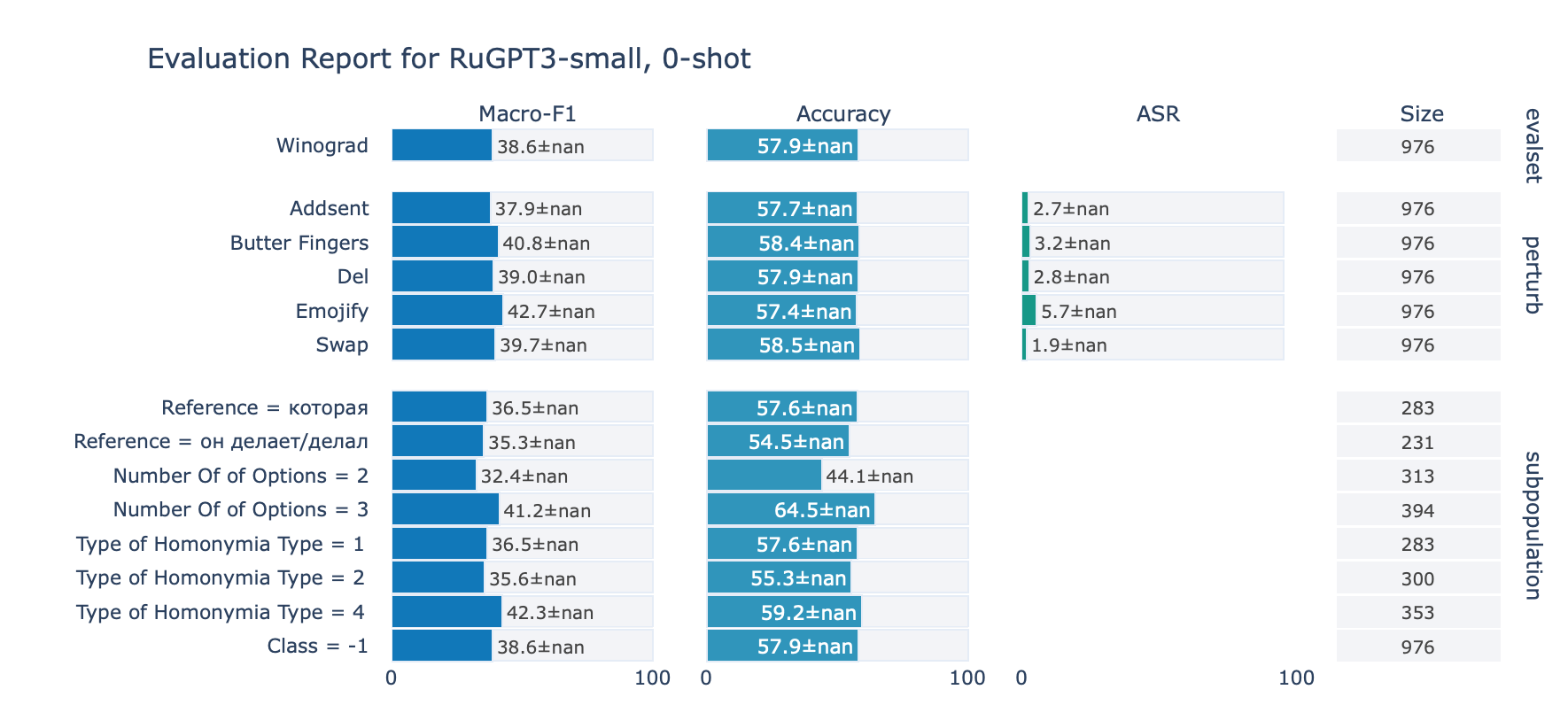
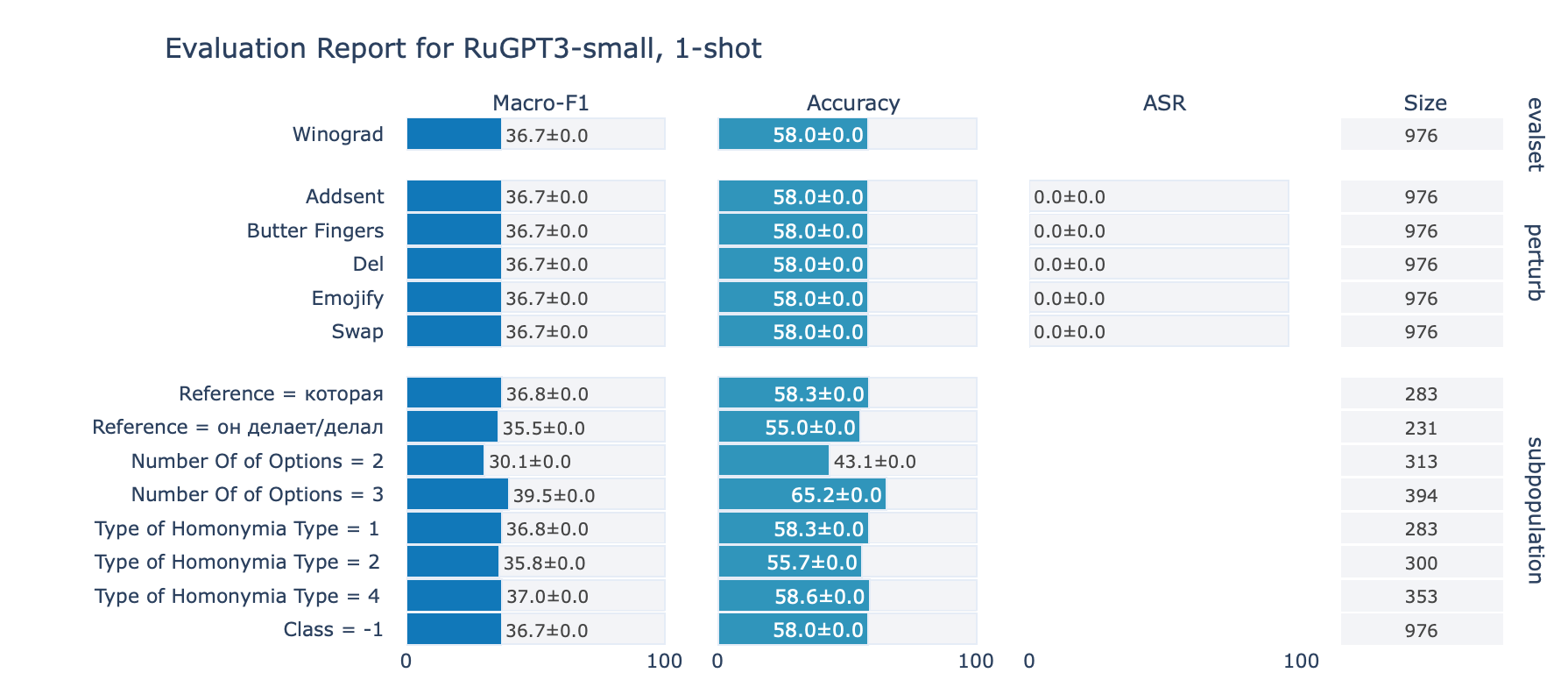
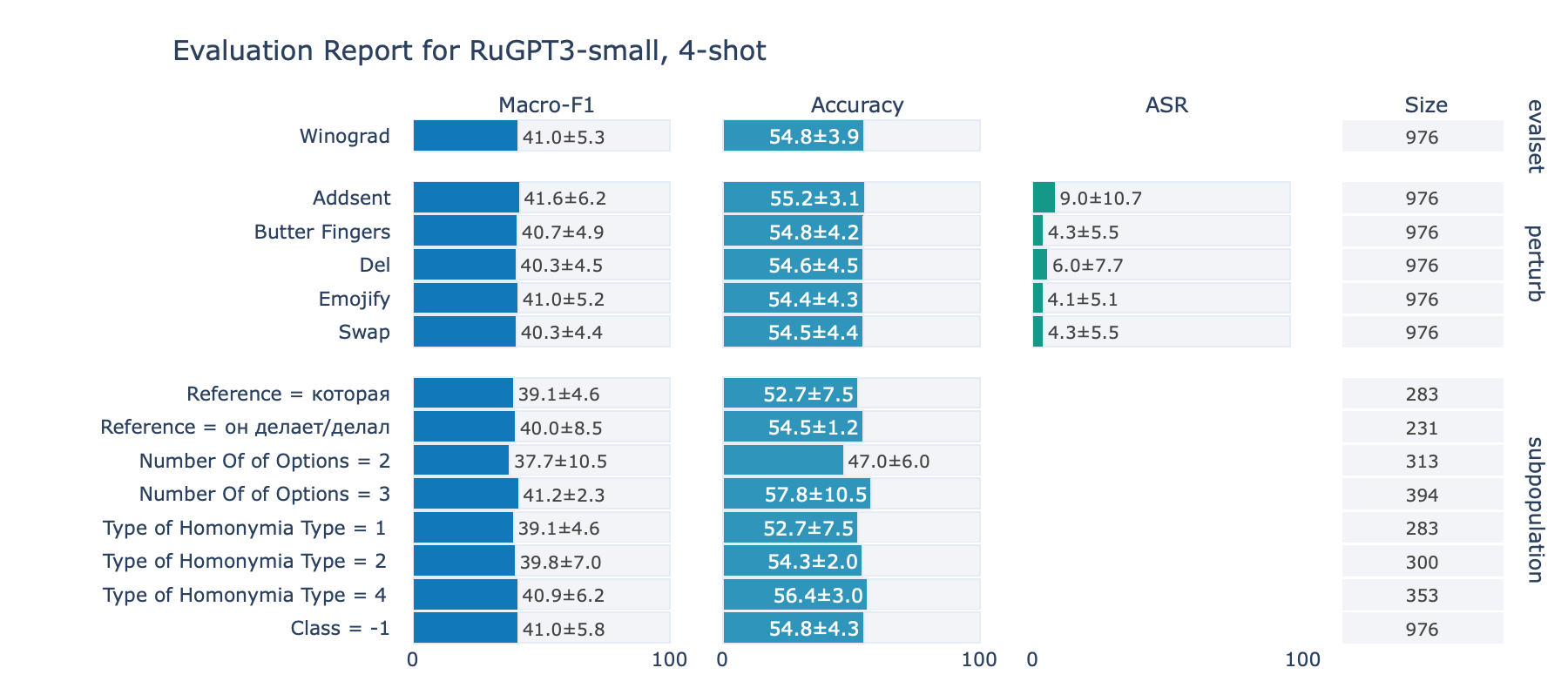
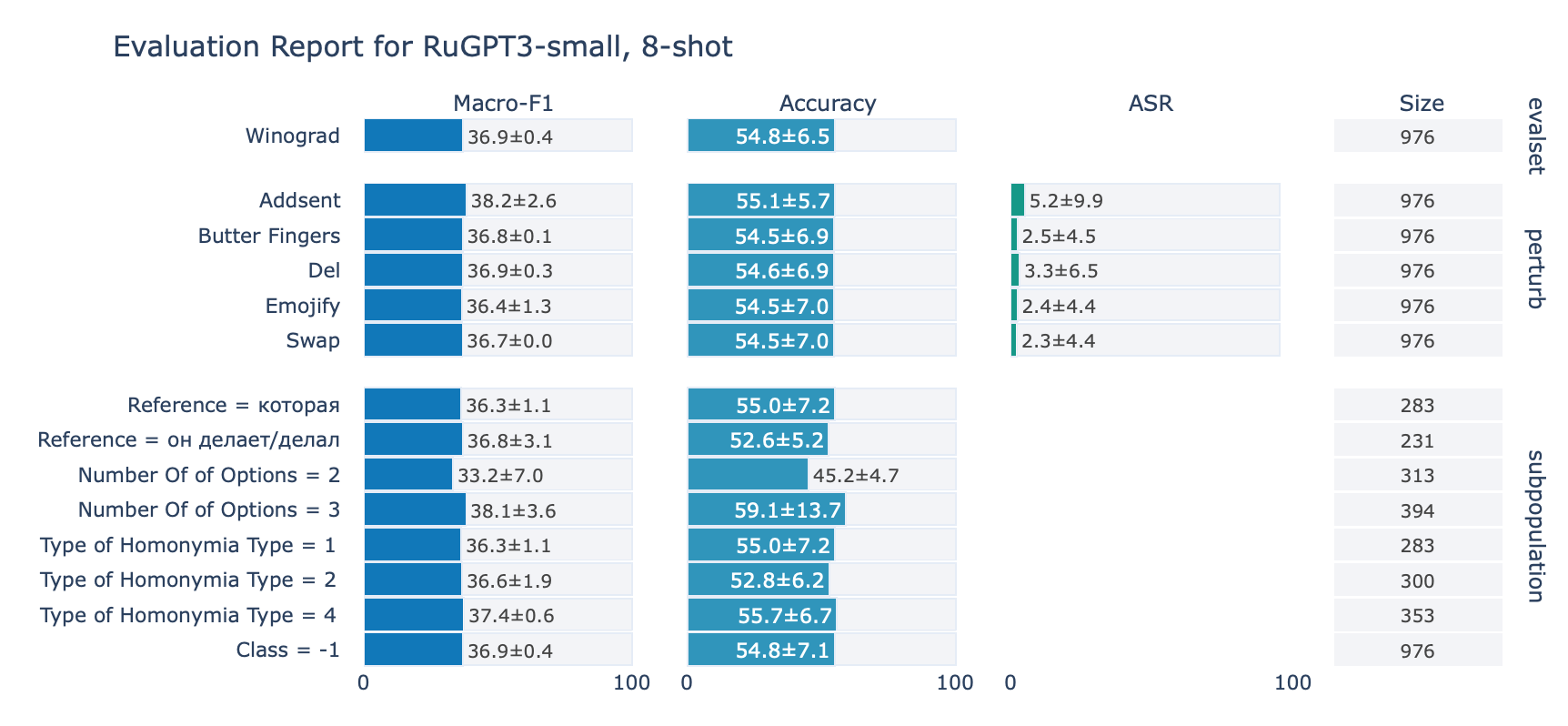
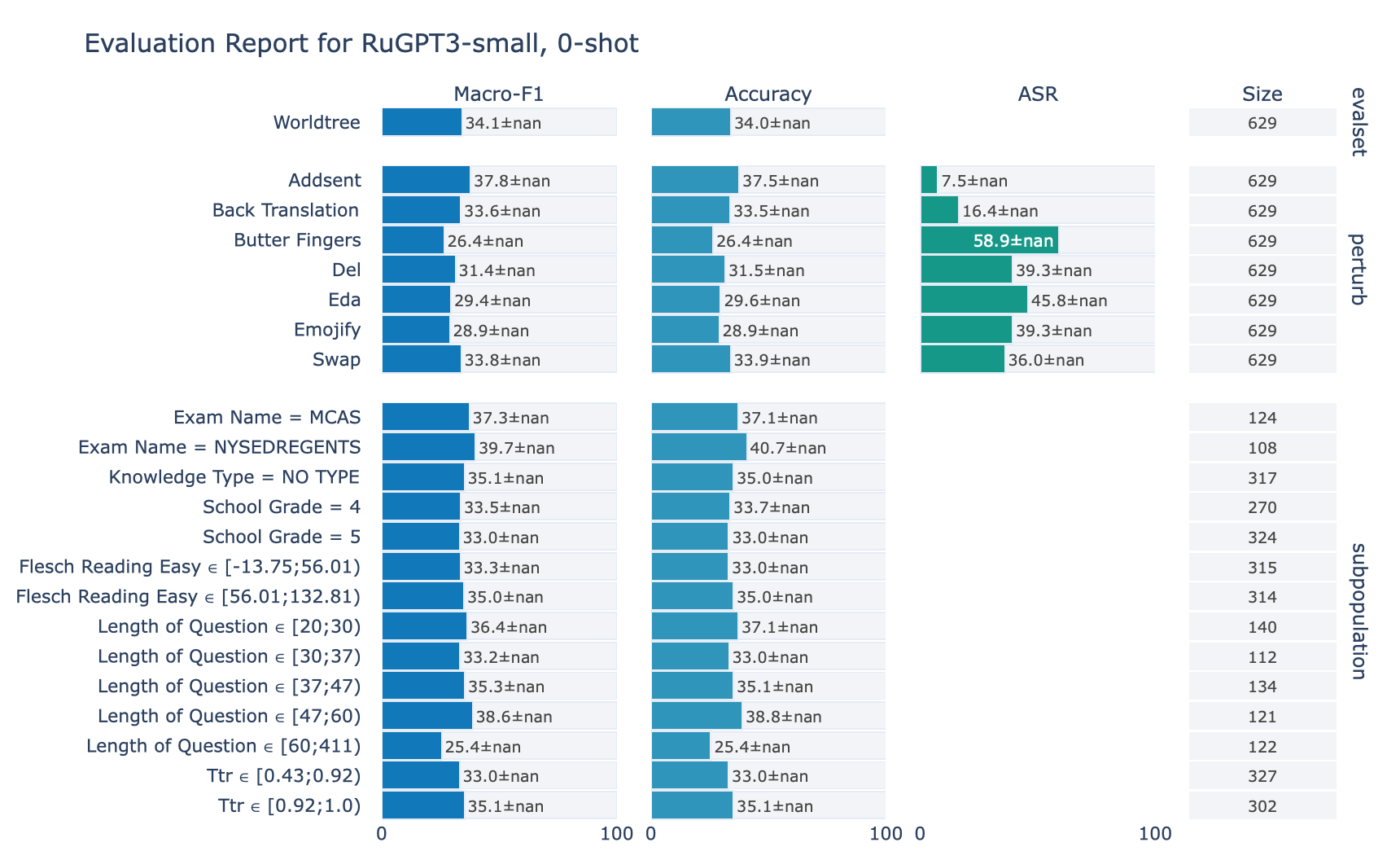
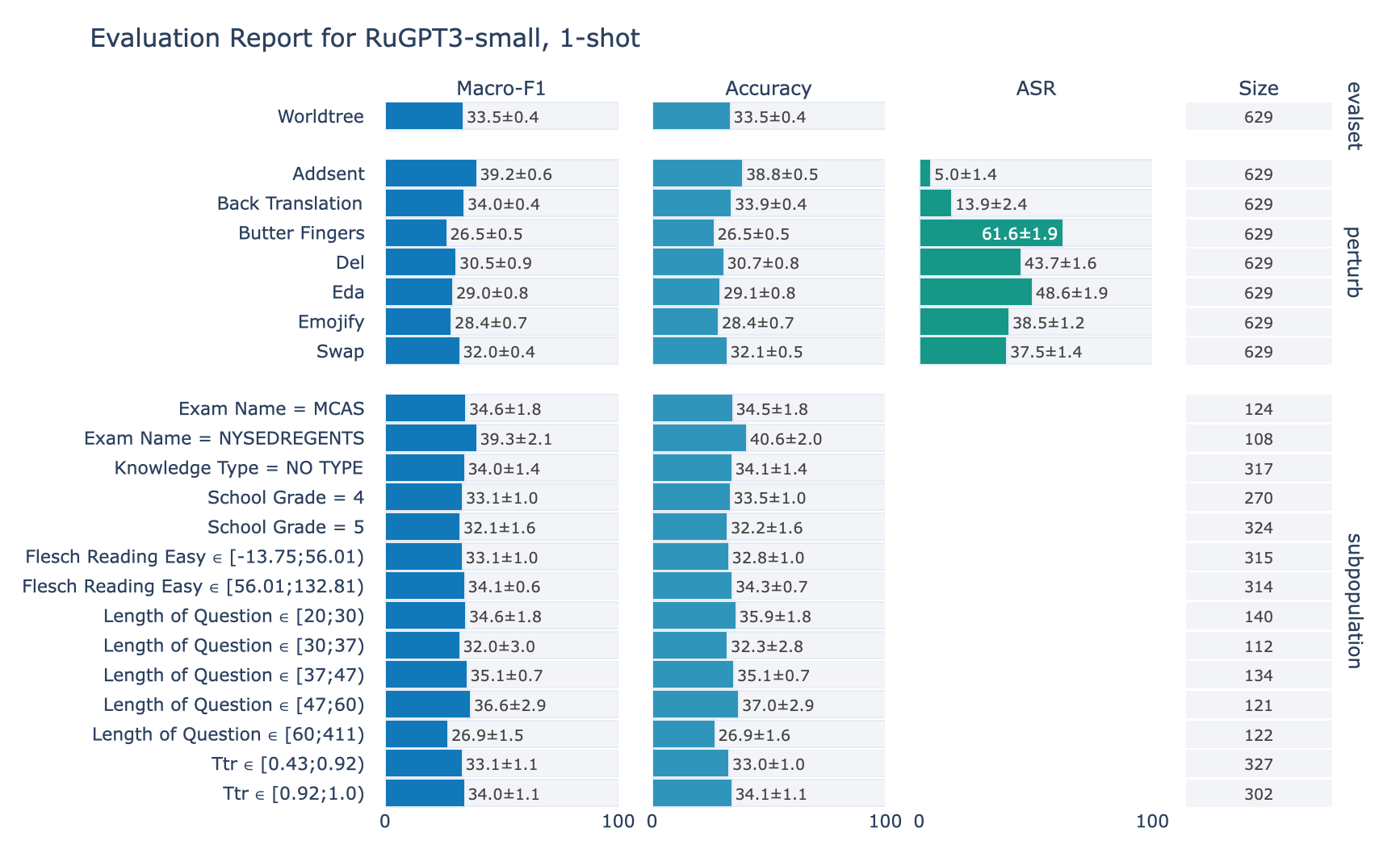
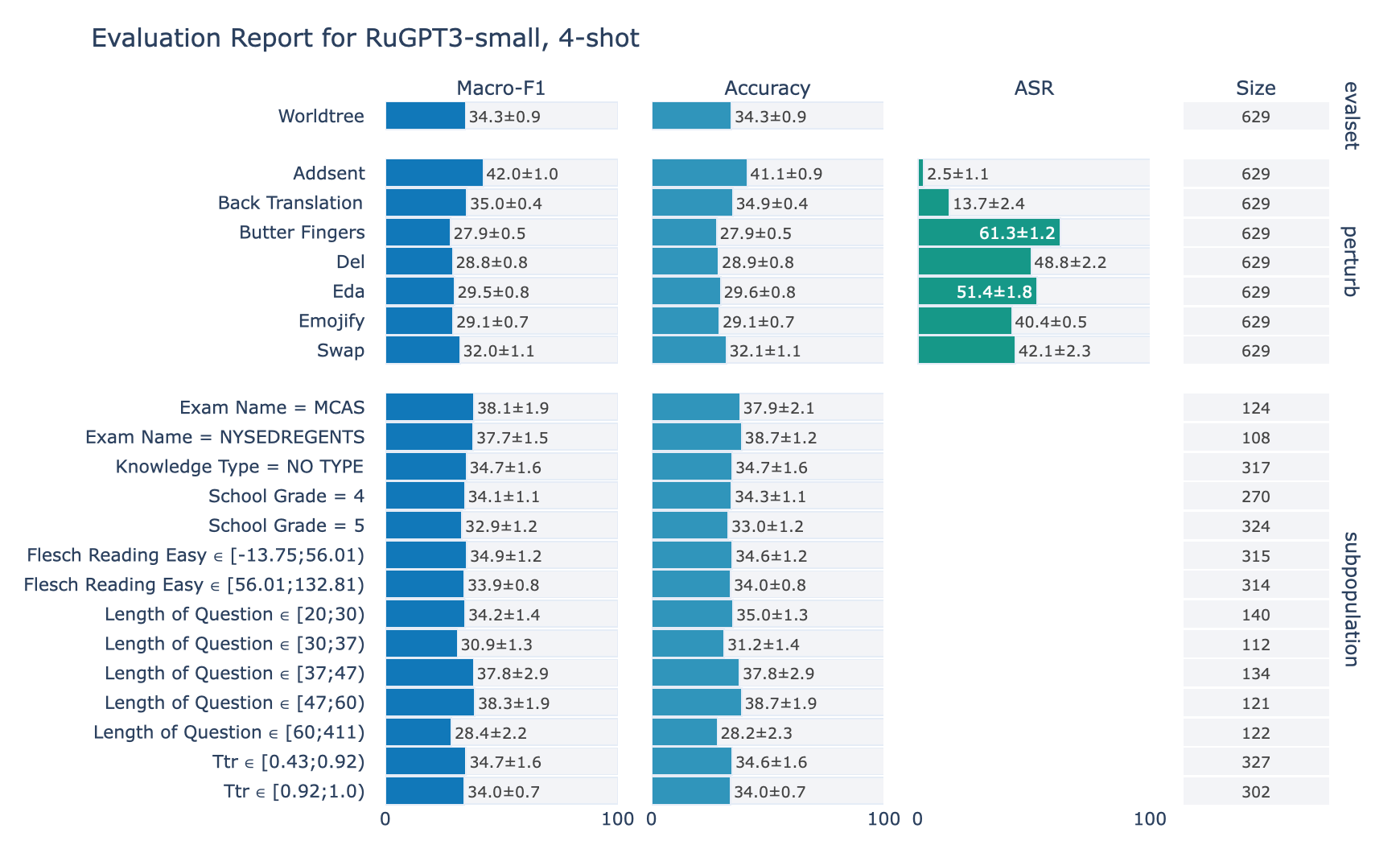
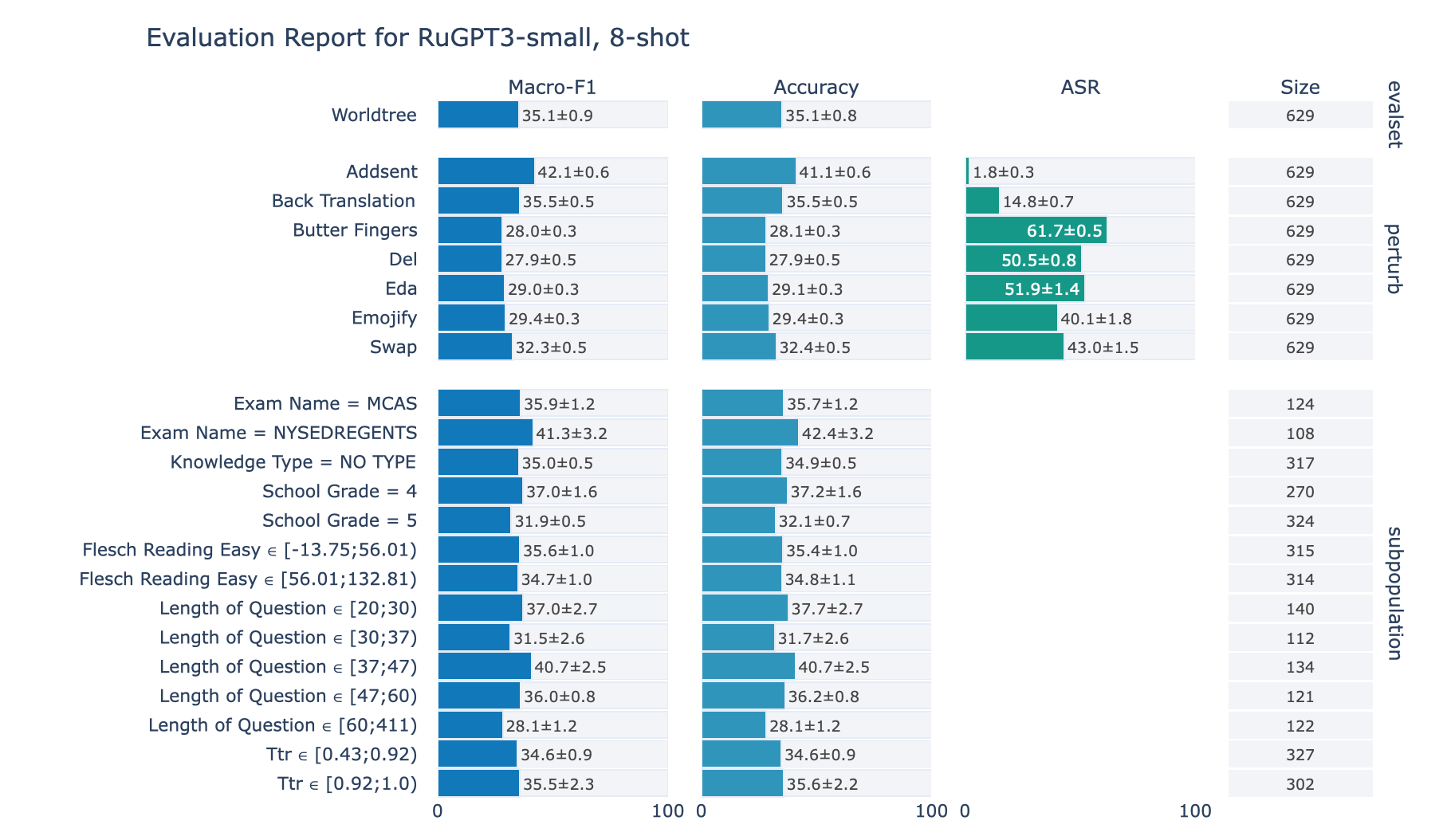
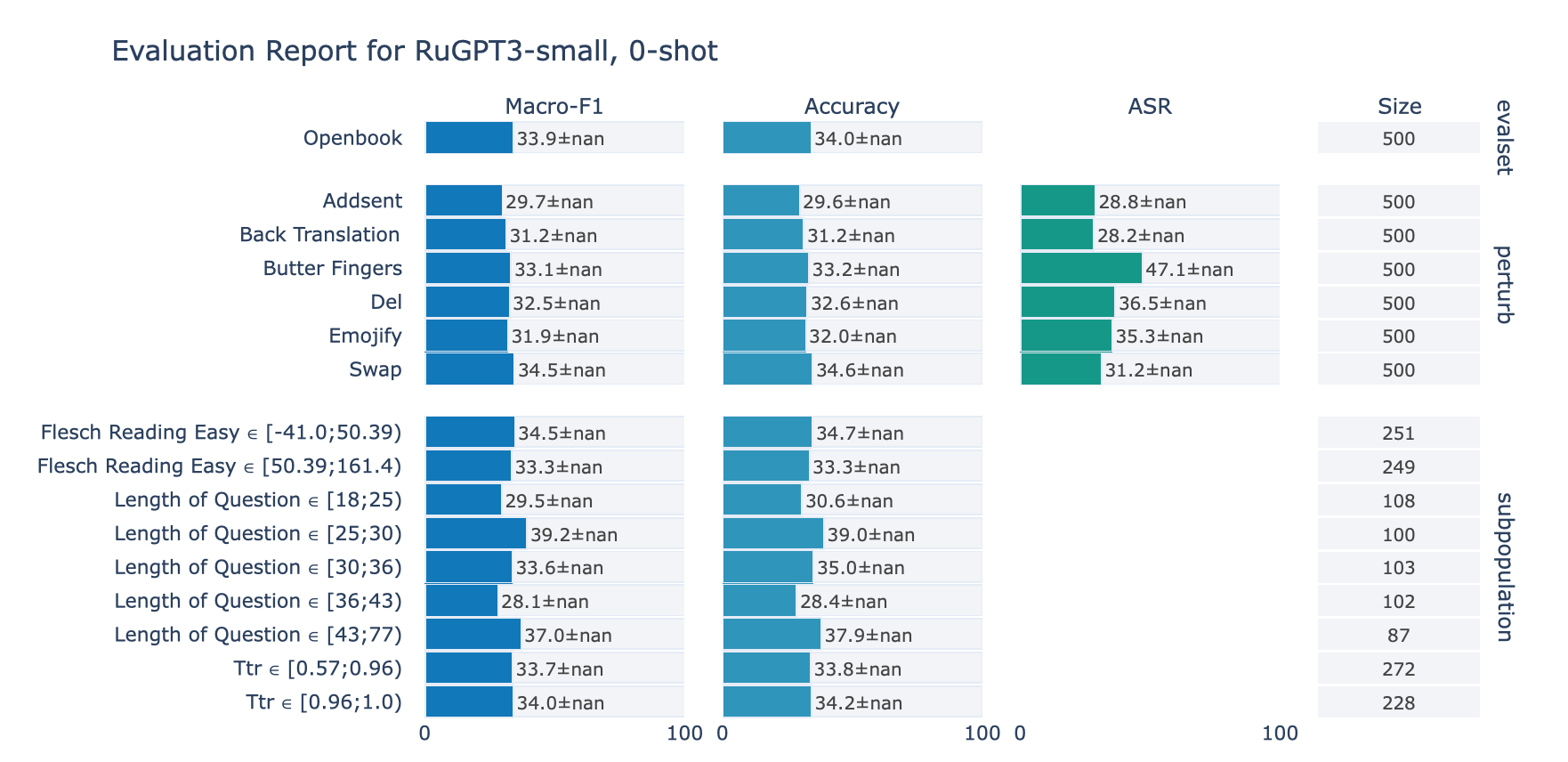
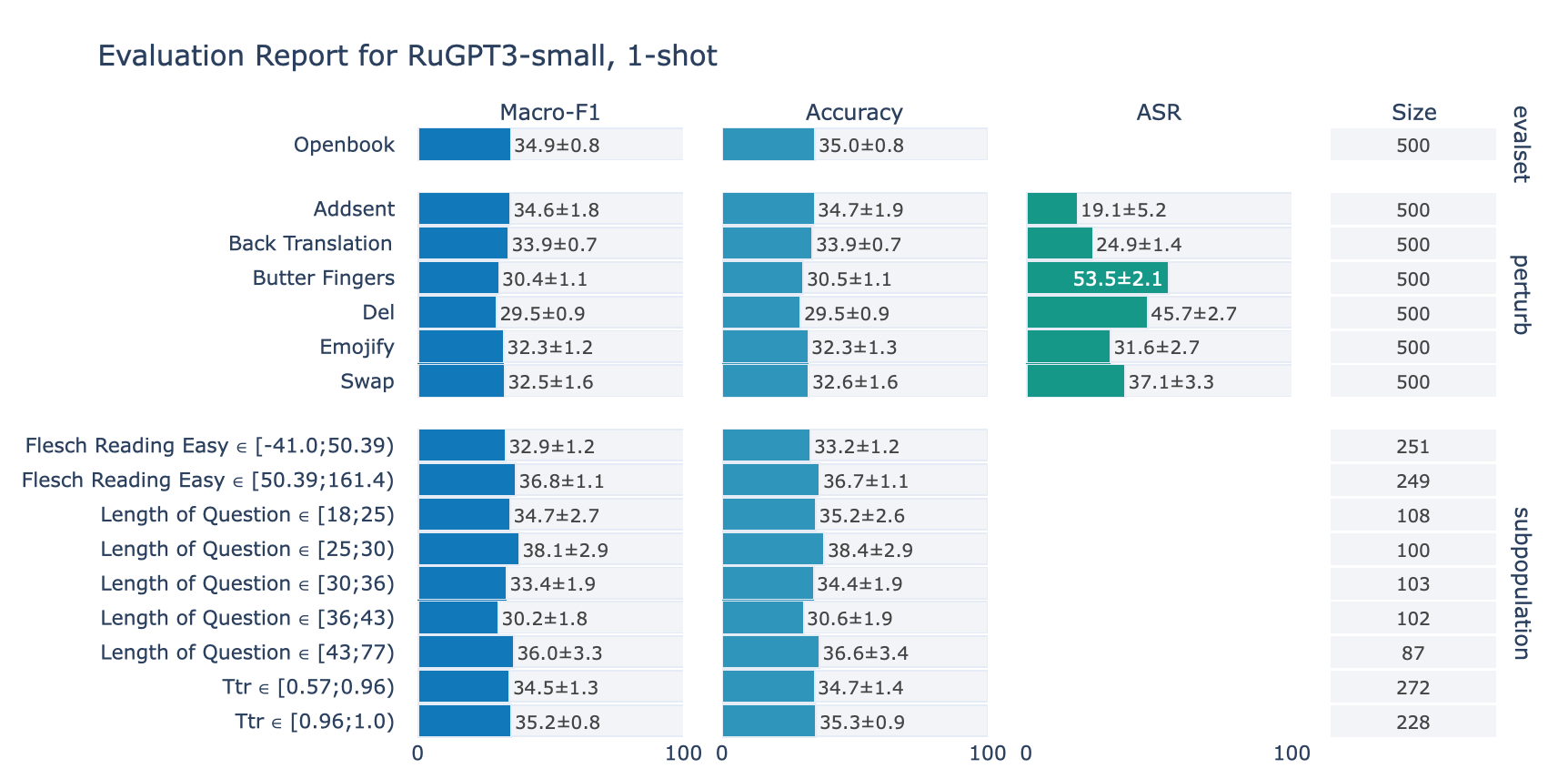
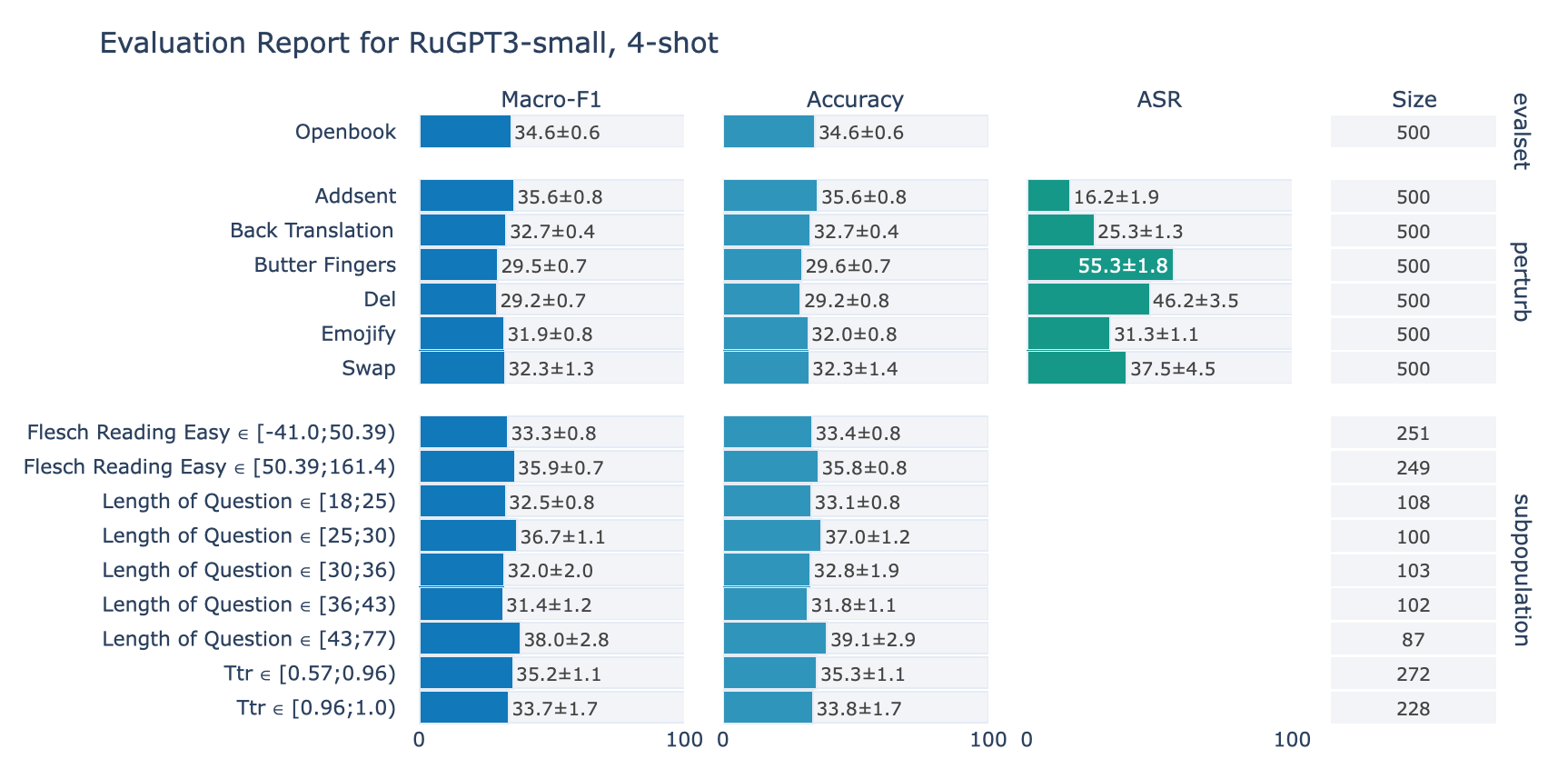
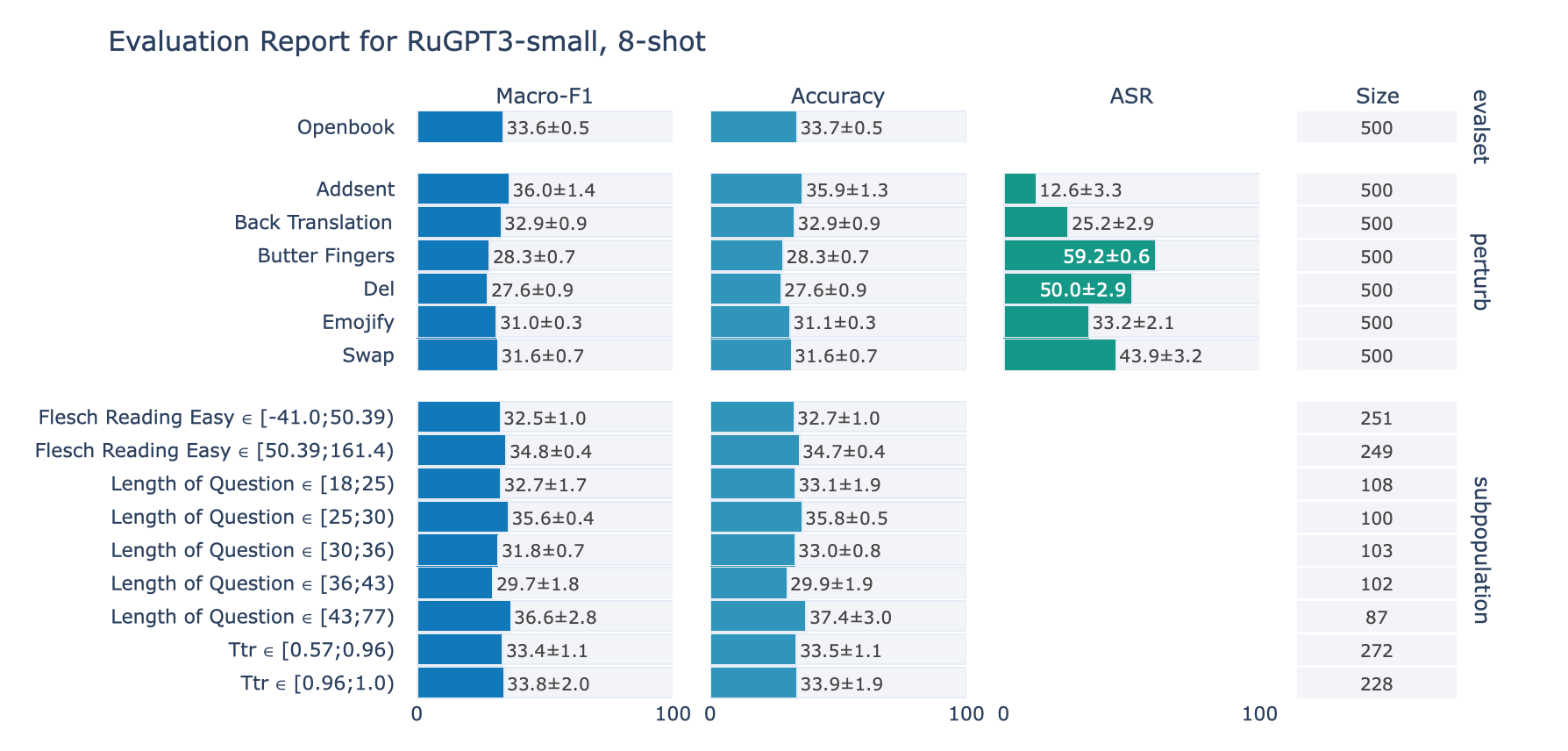
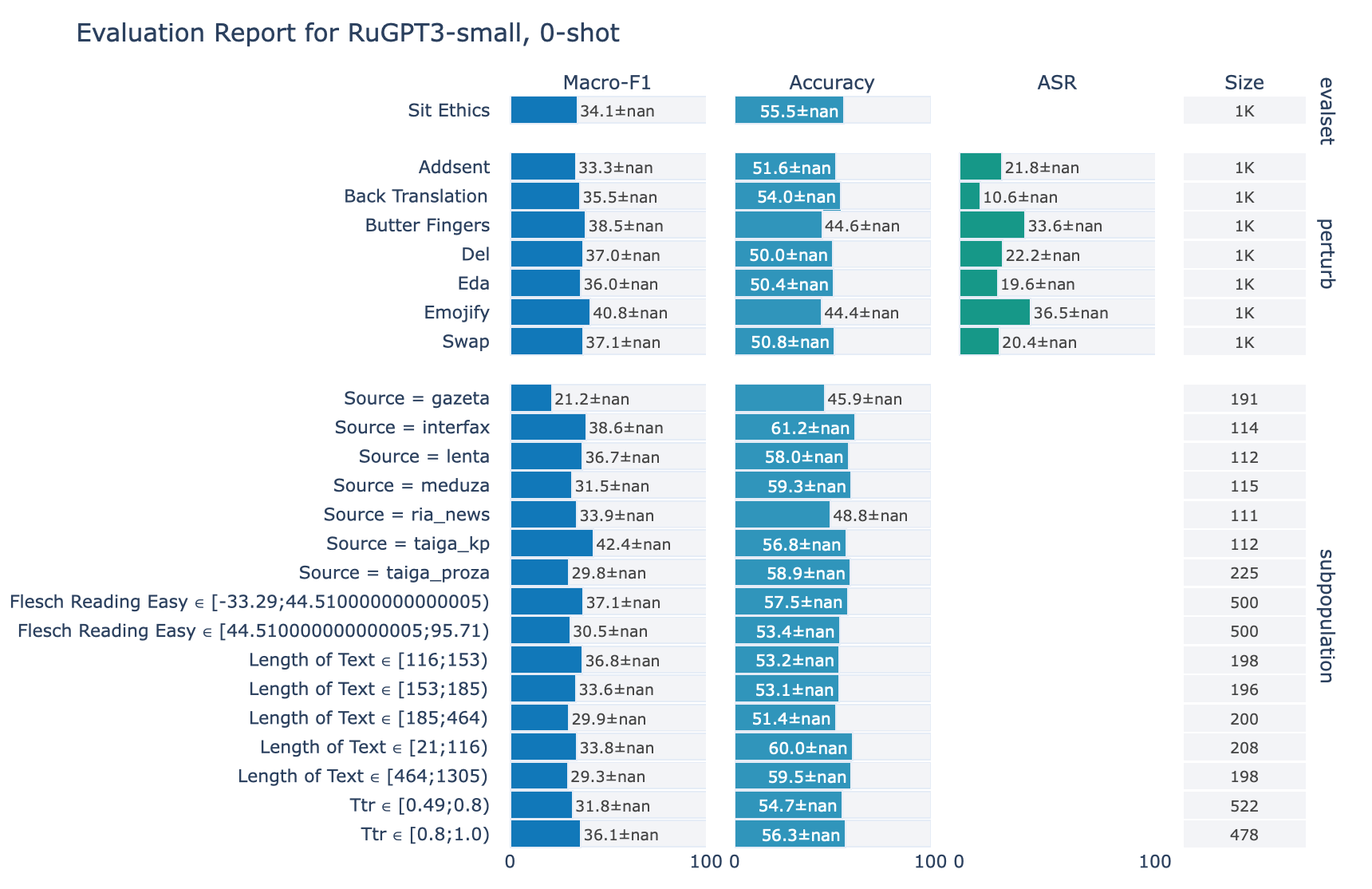
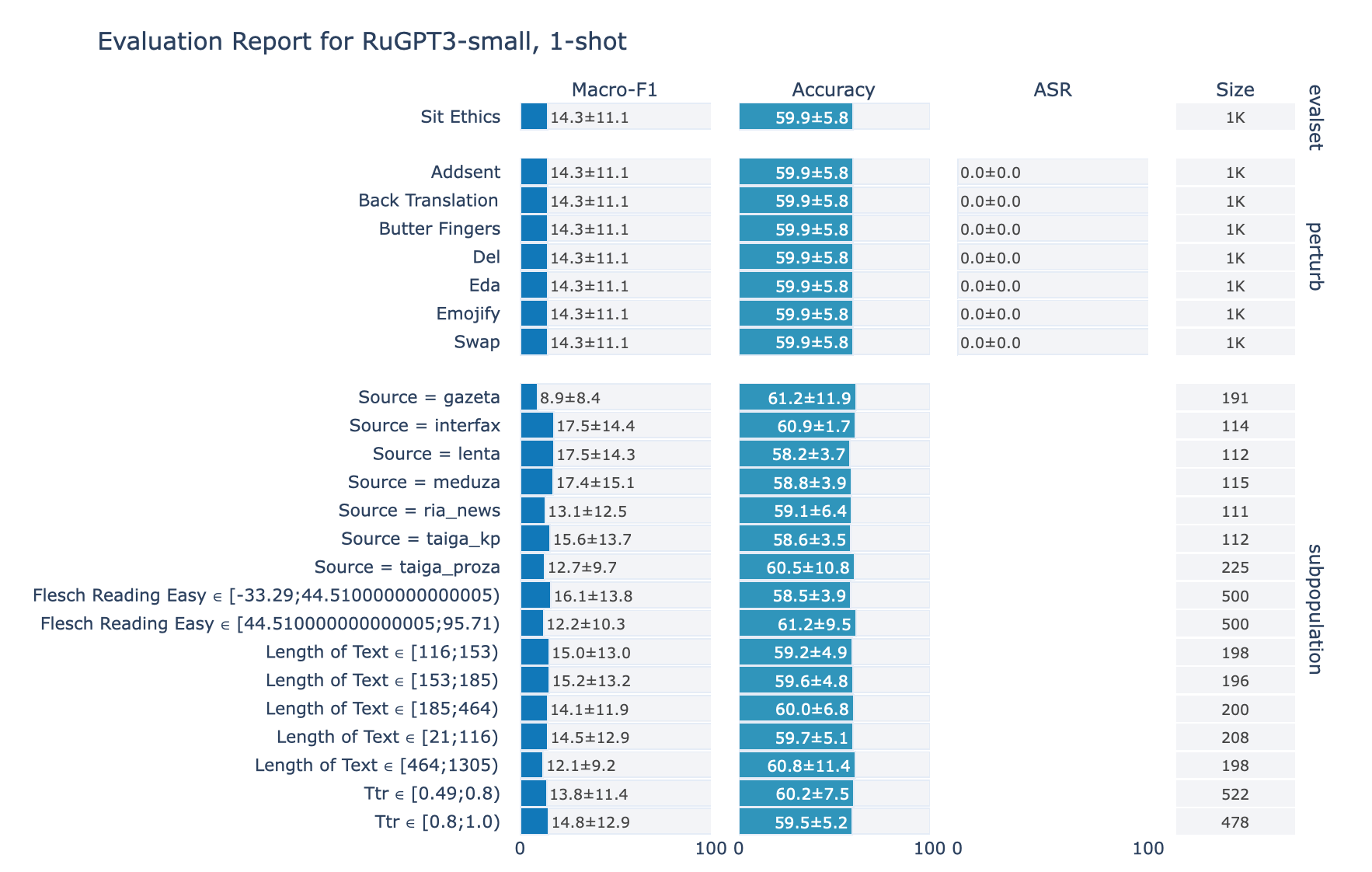
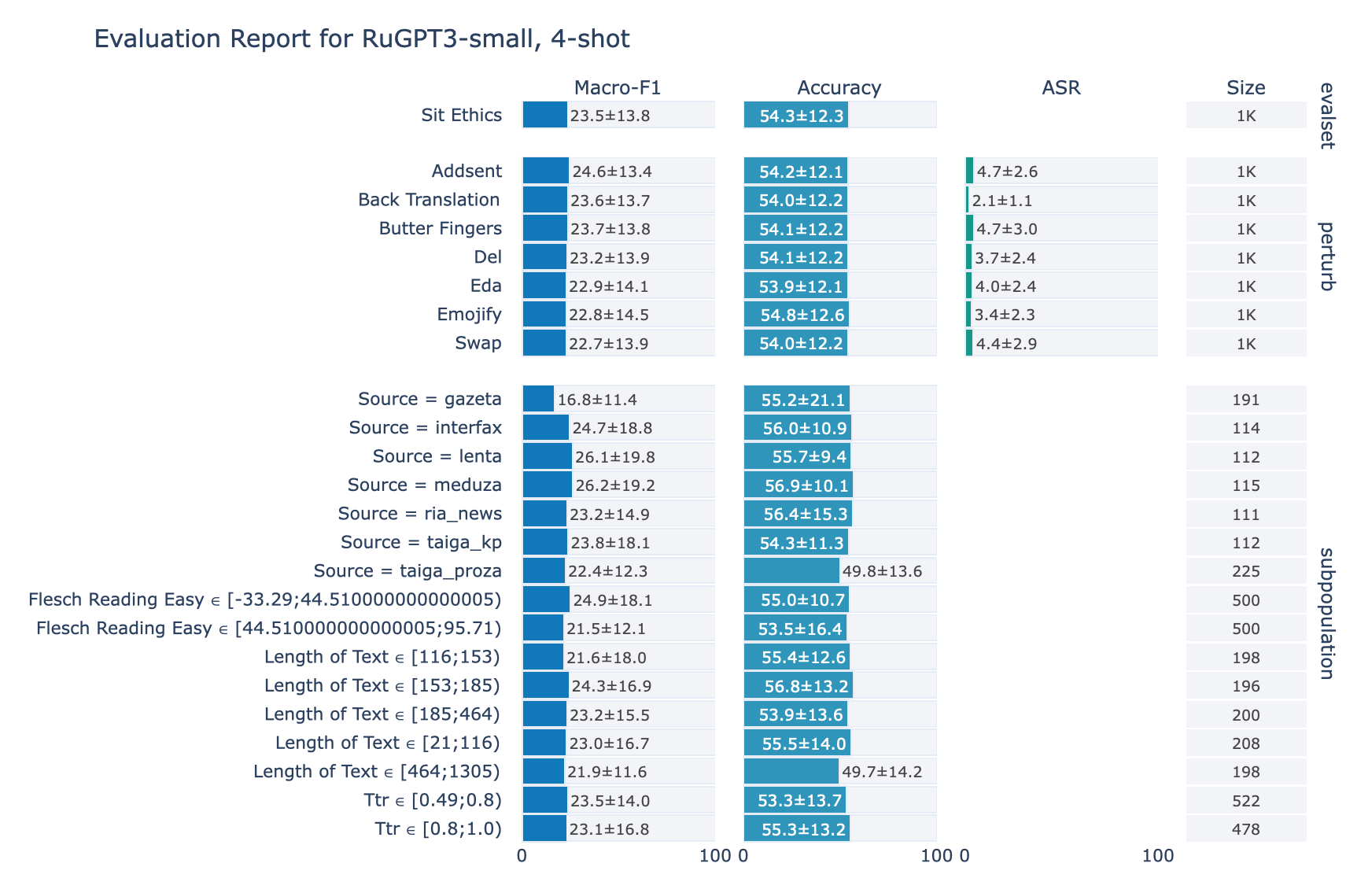
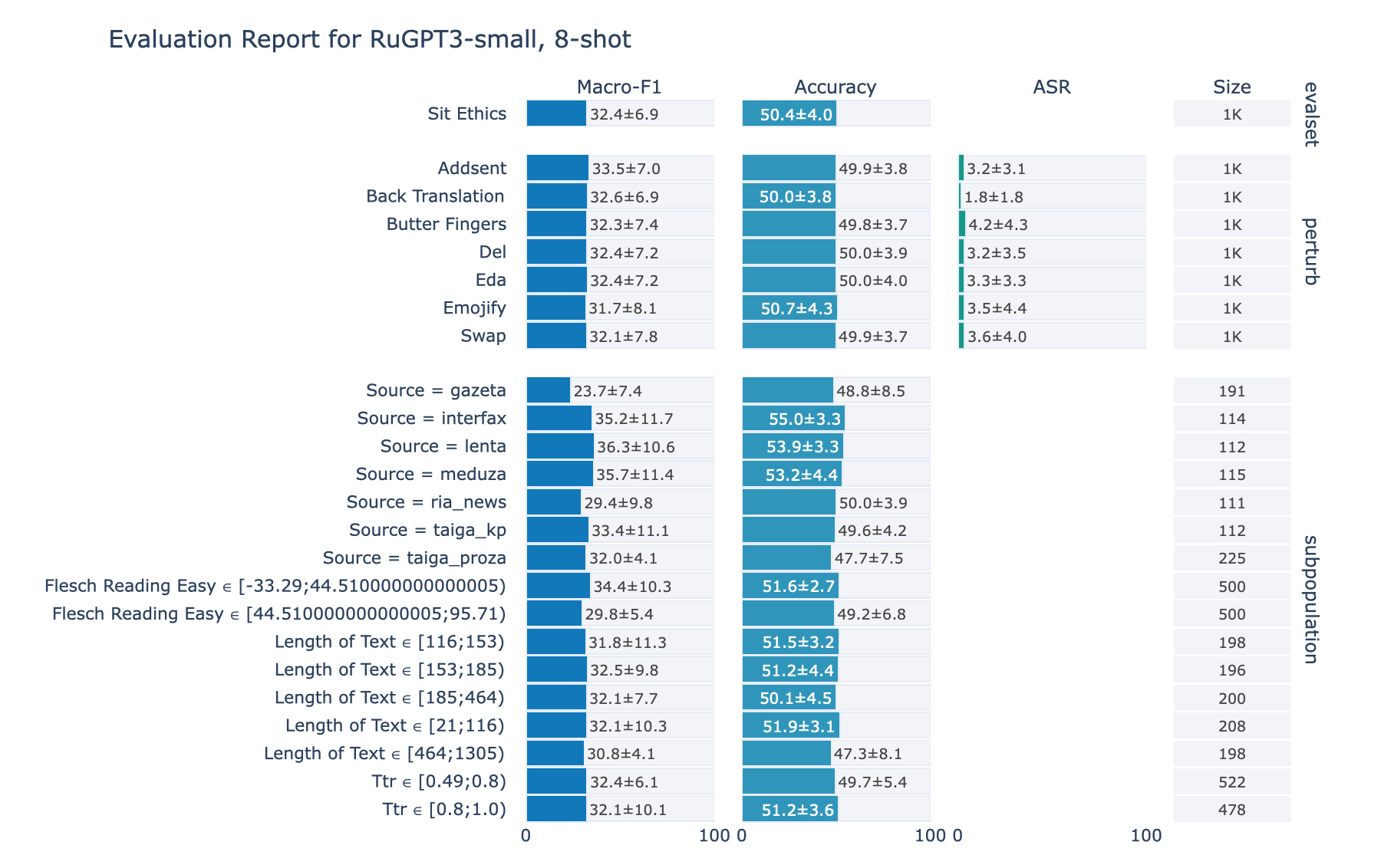
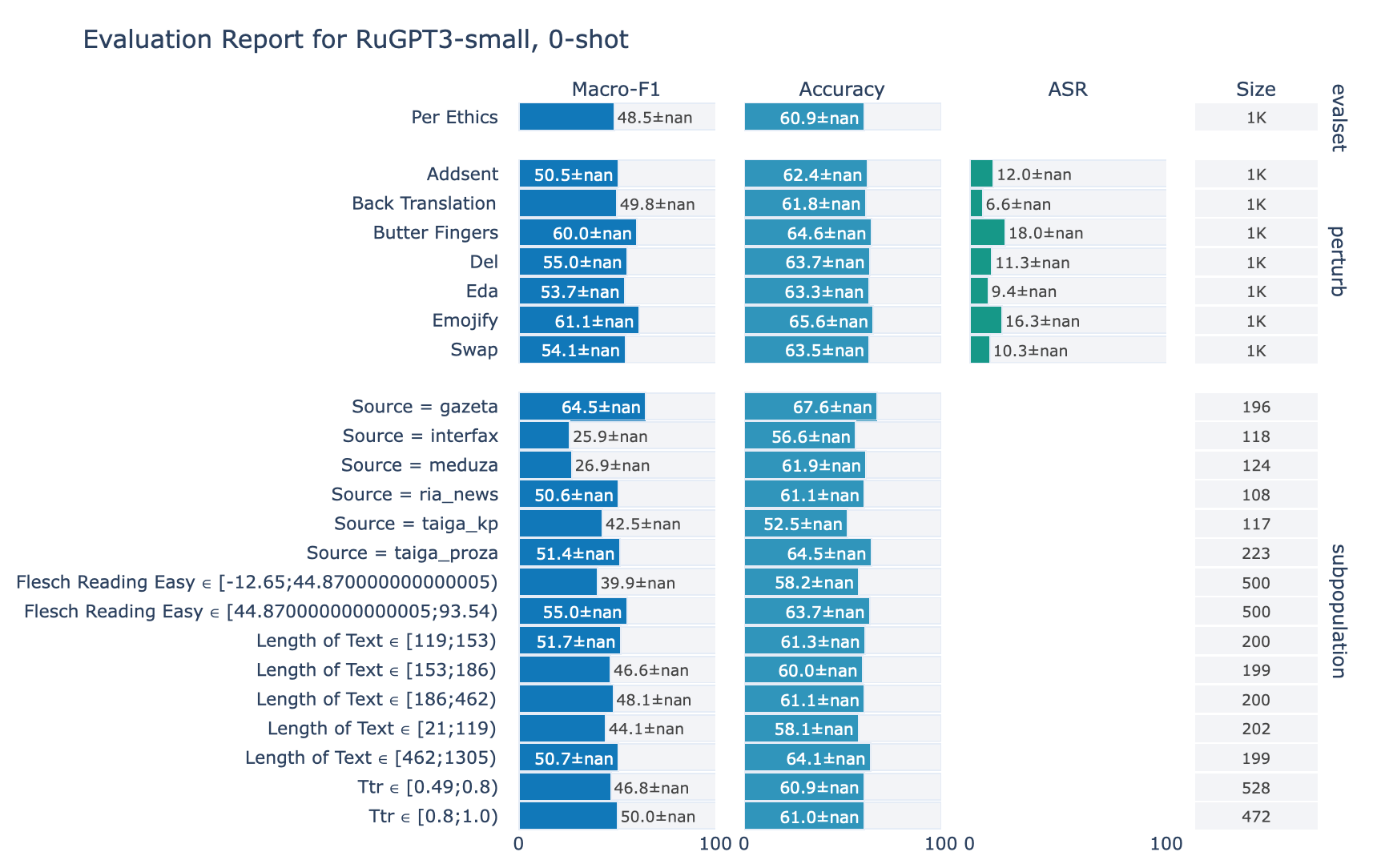
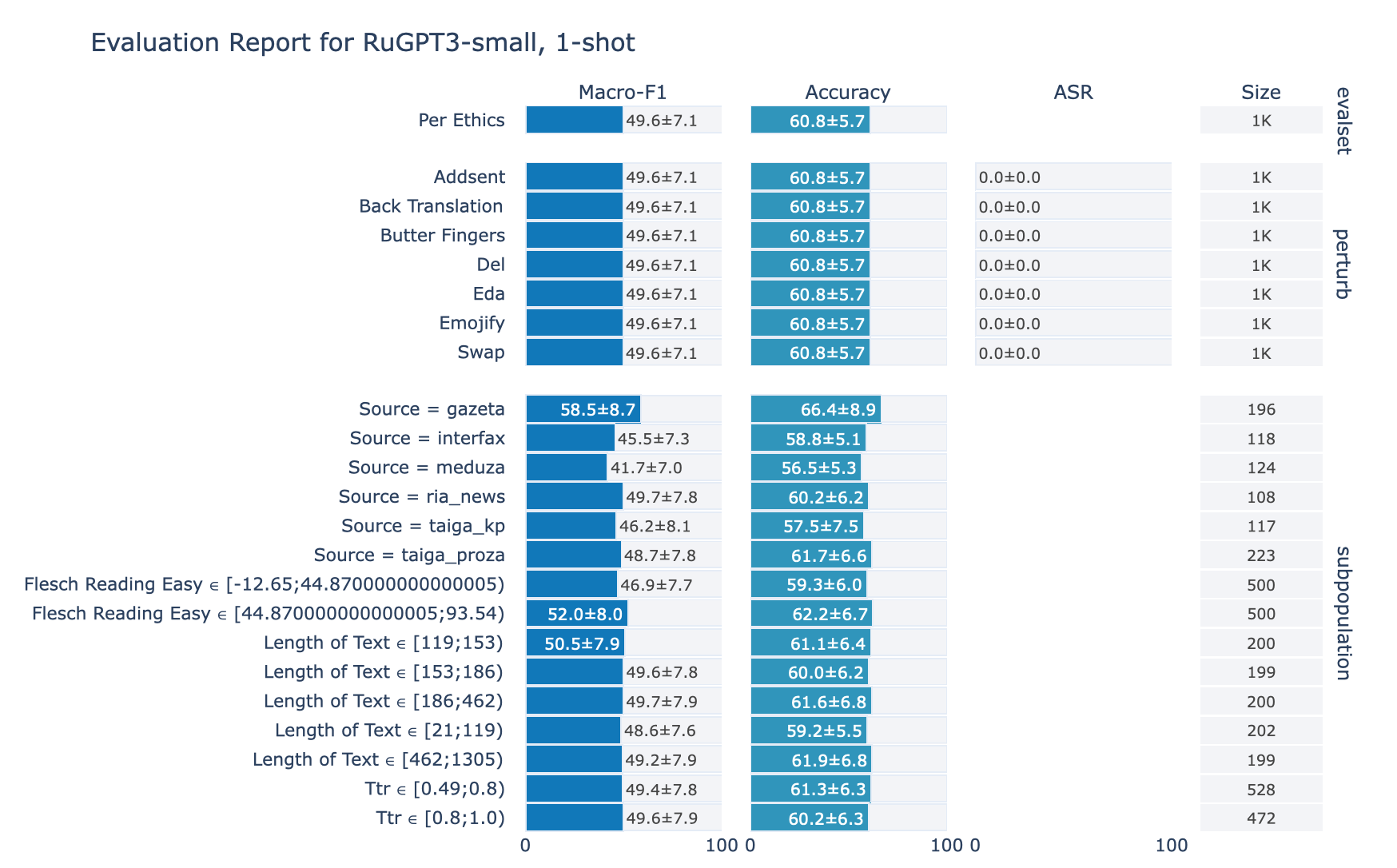
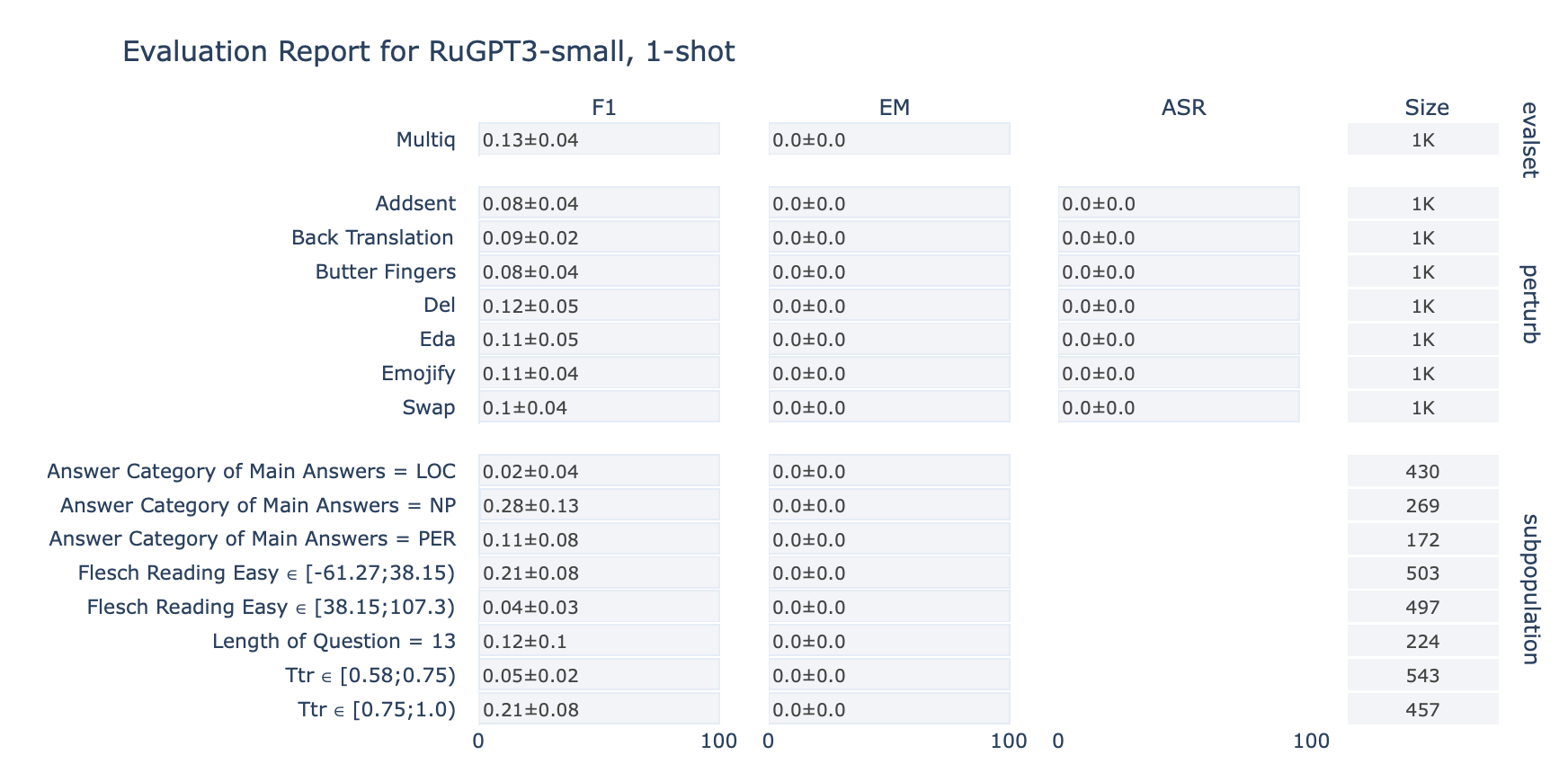
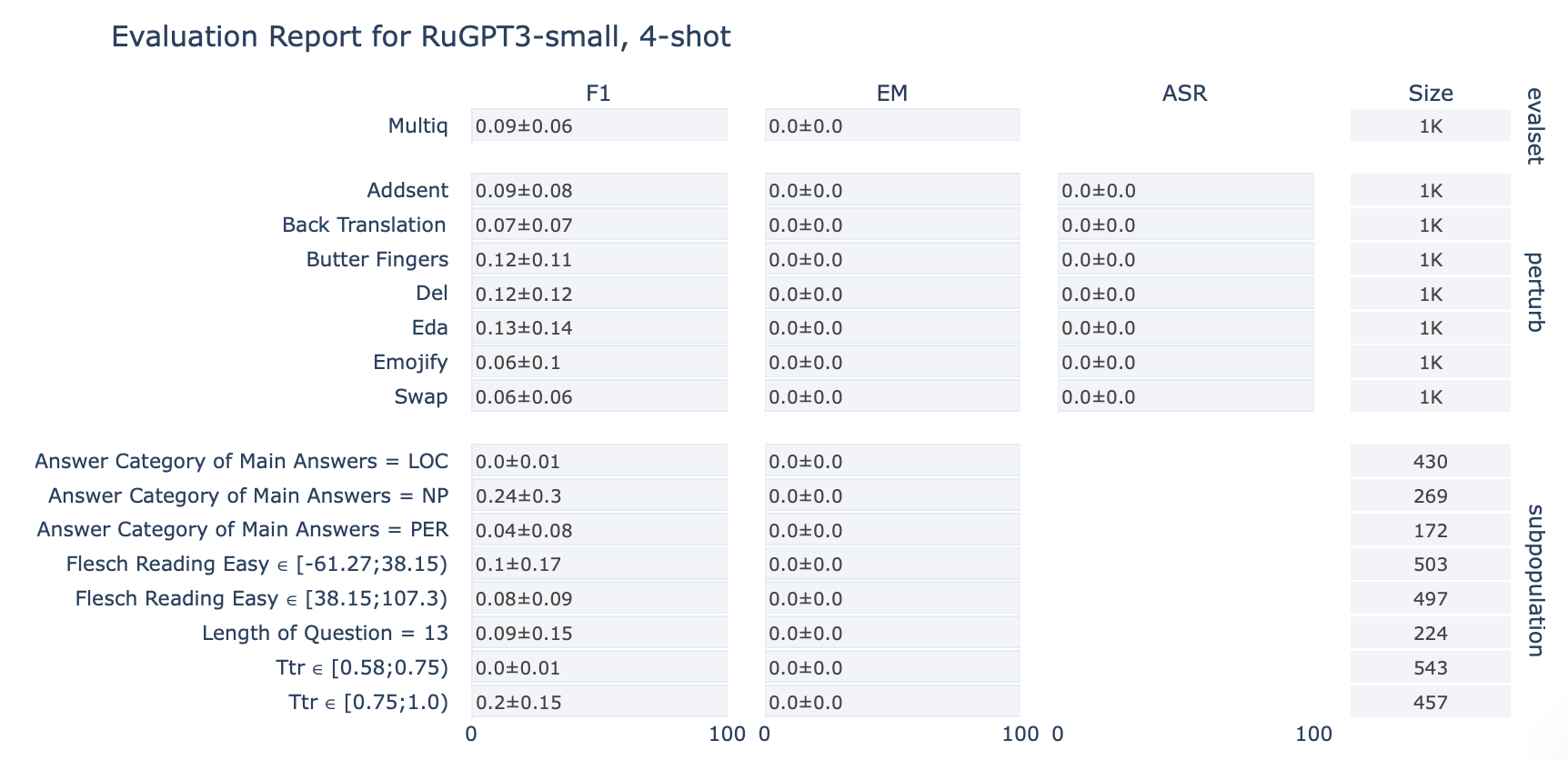
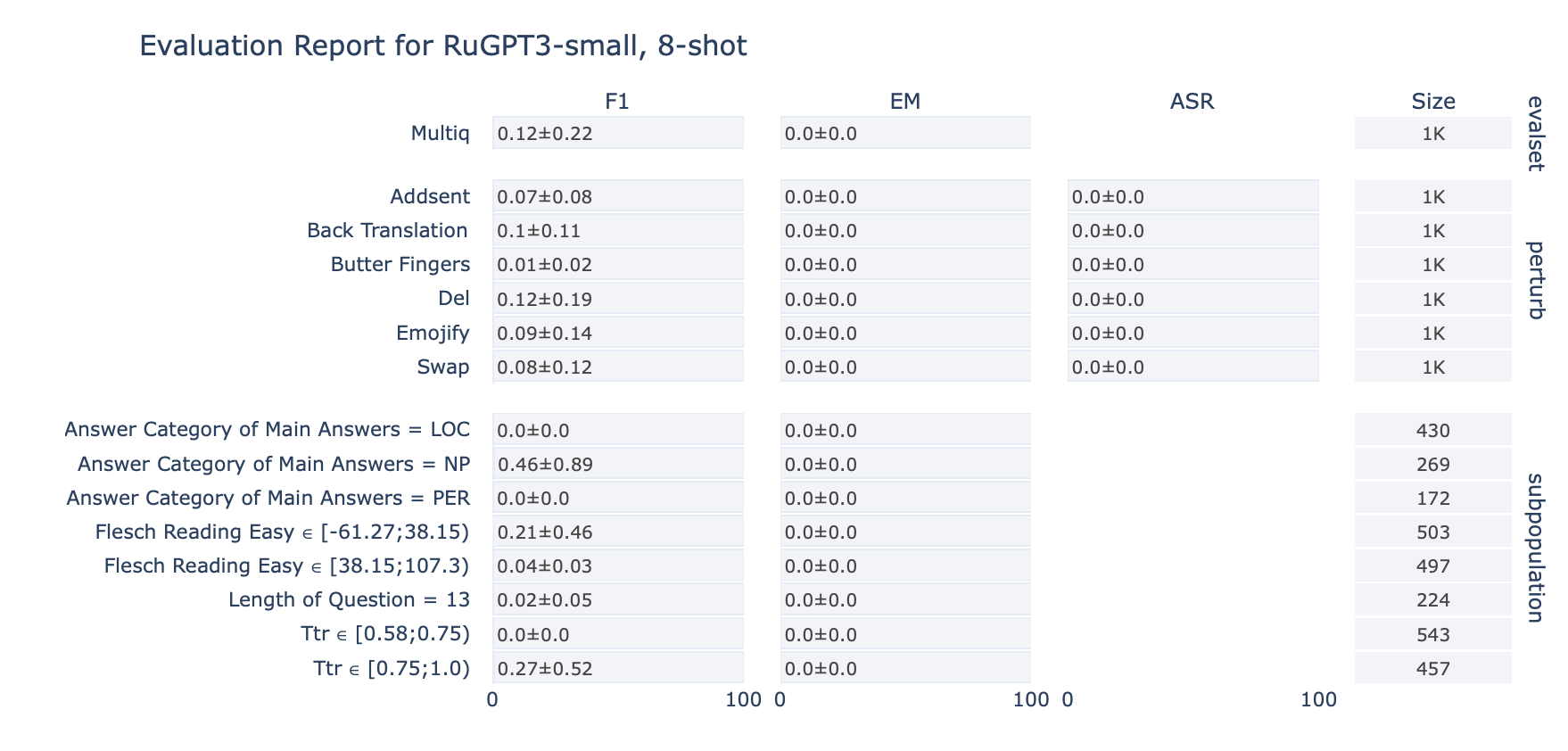
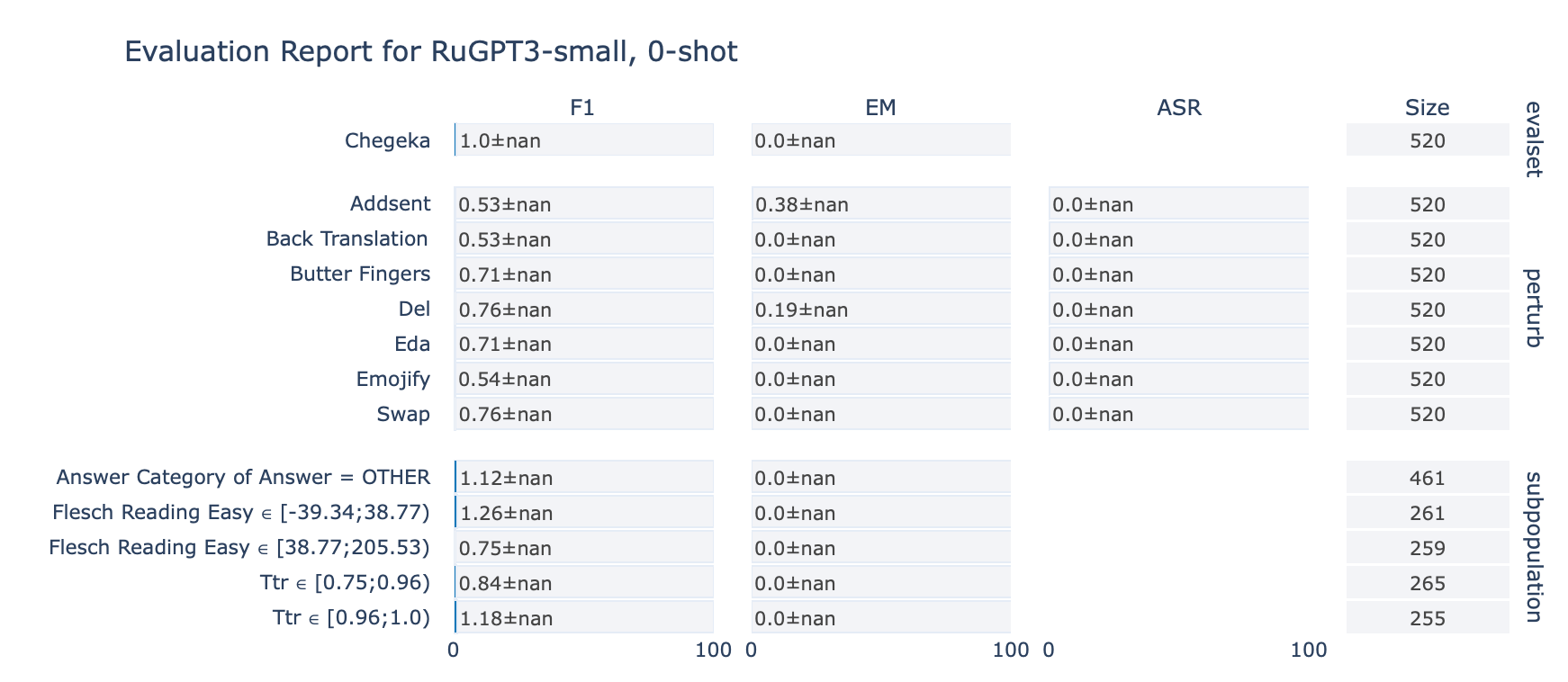
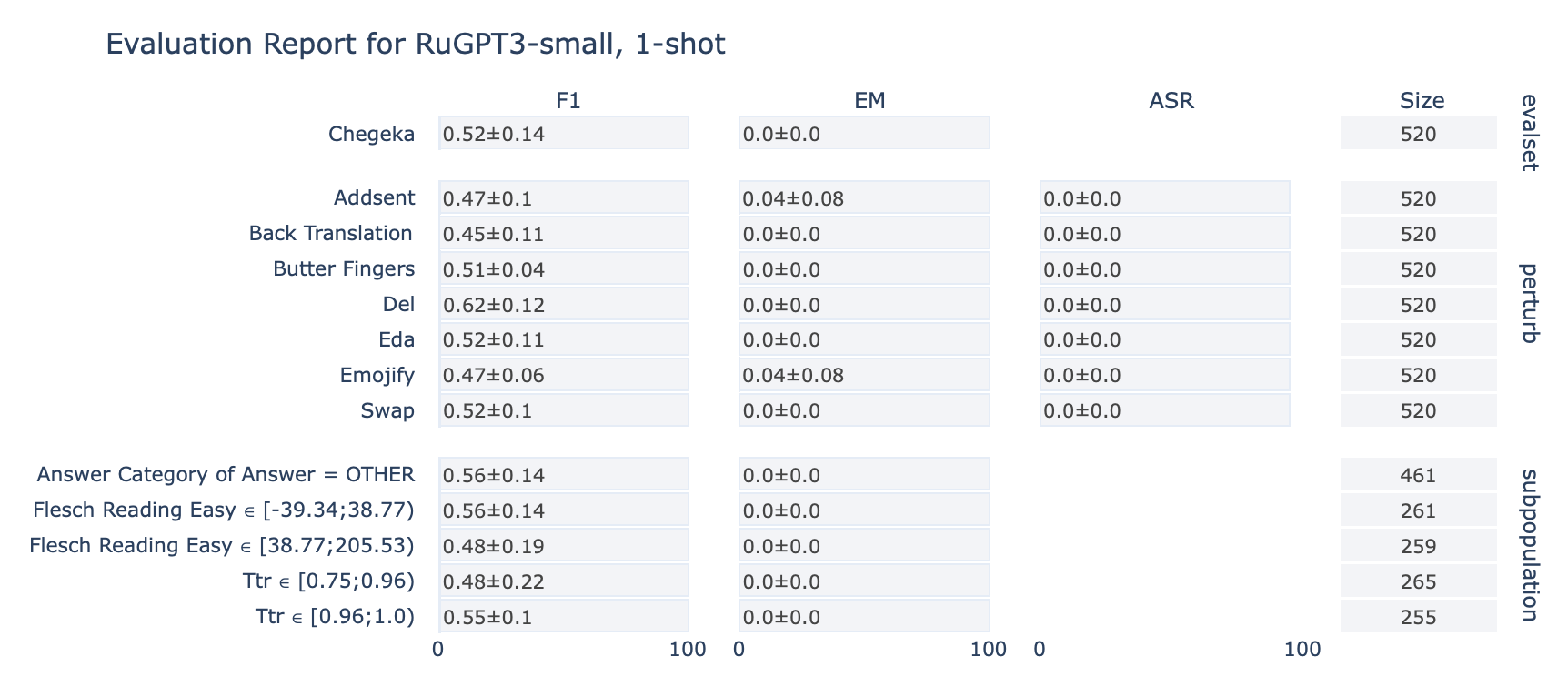
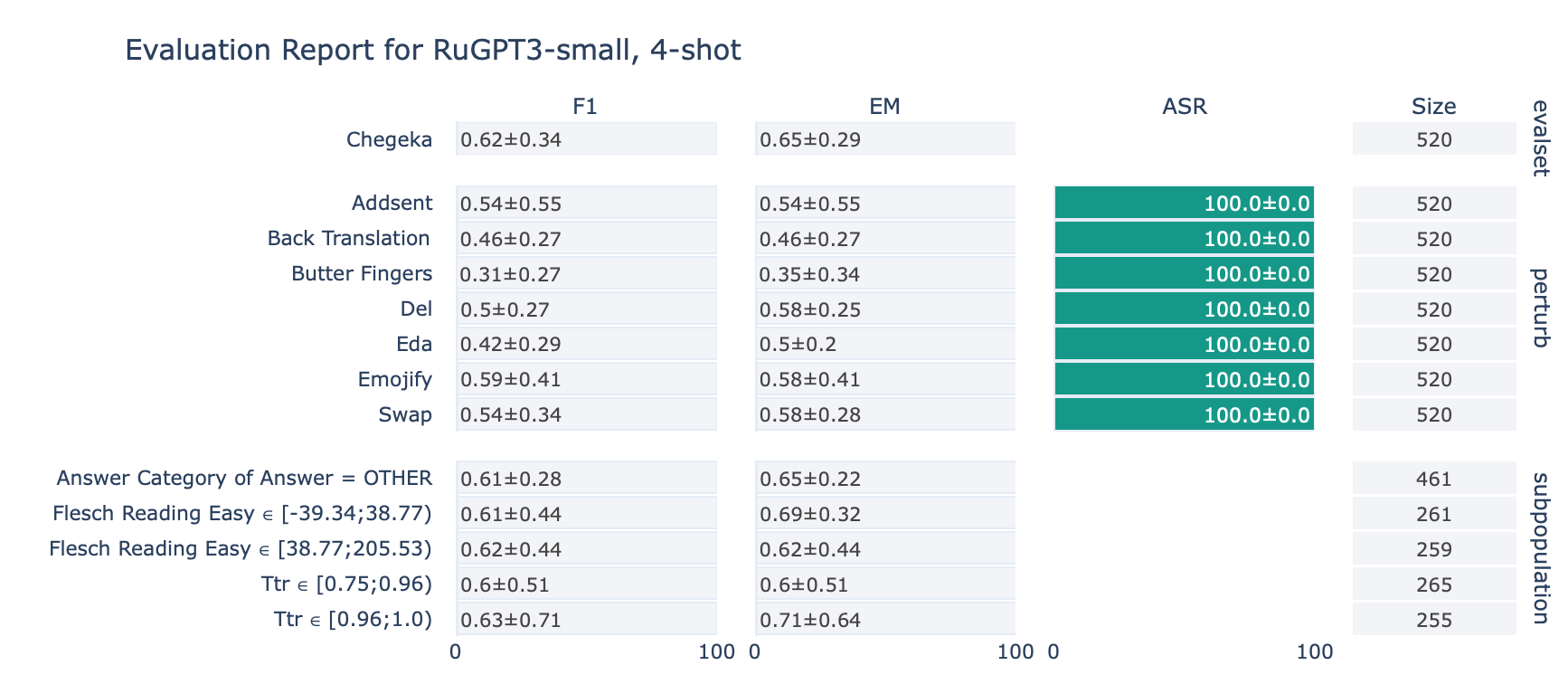
ruGPT-3 Small
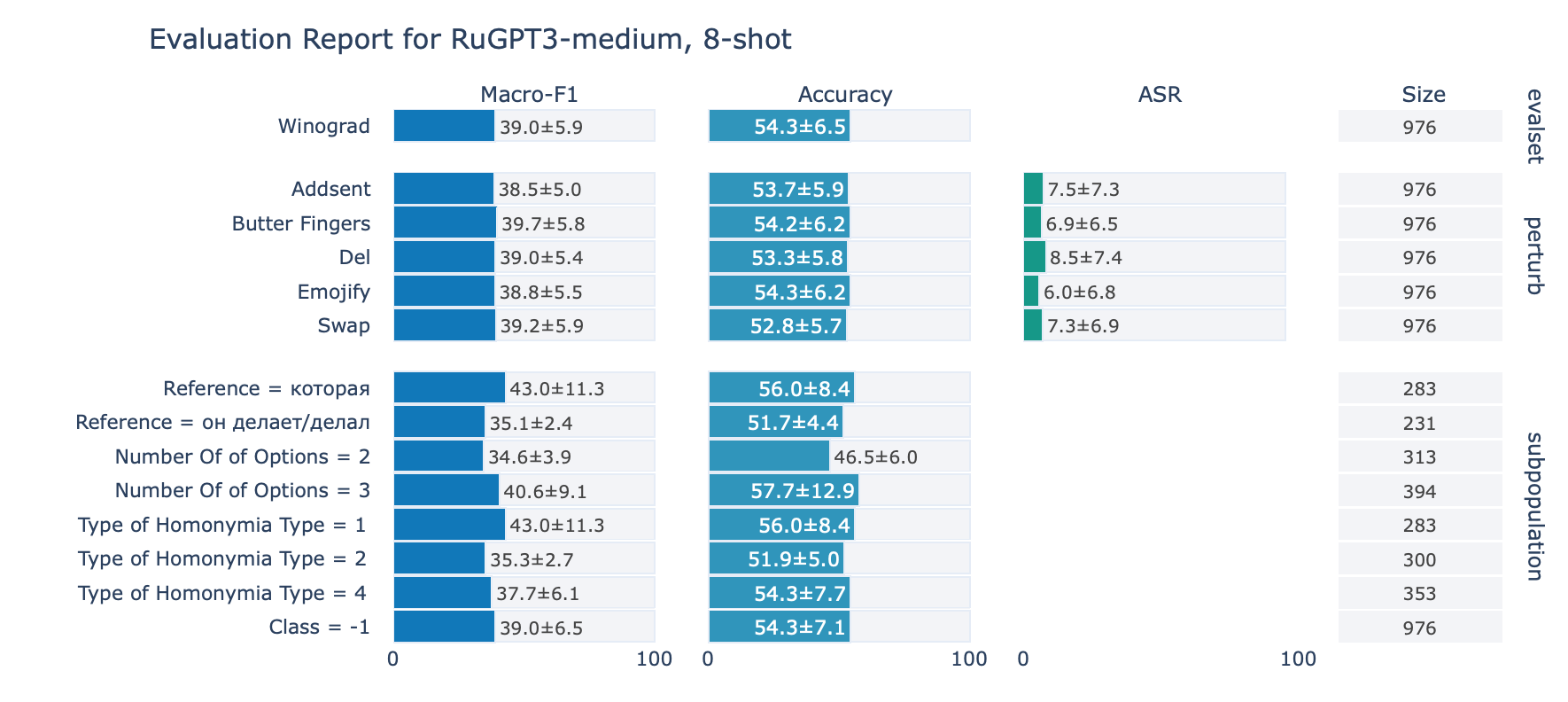
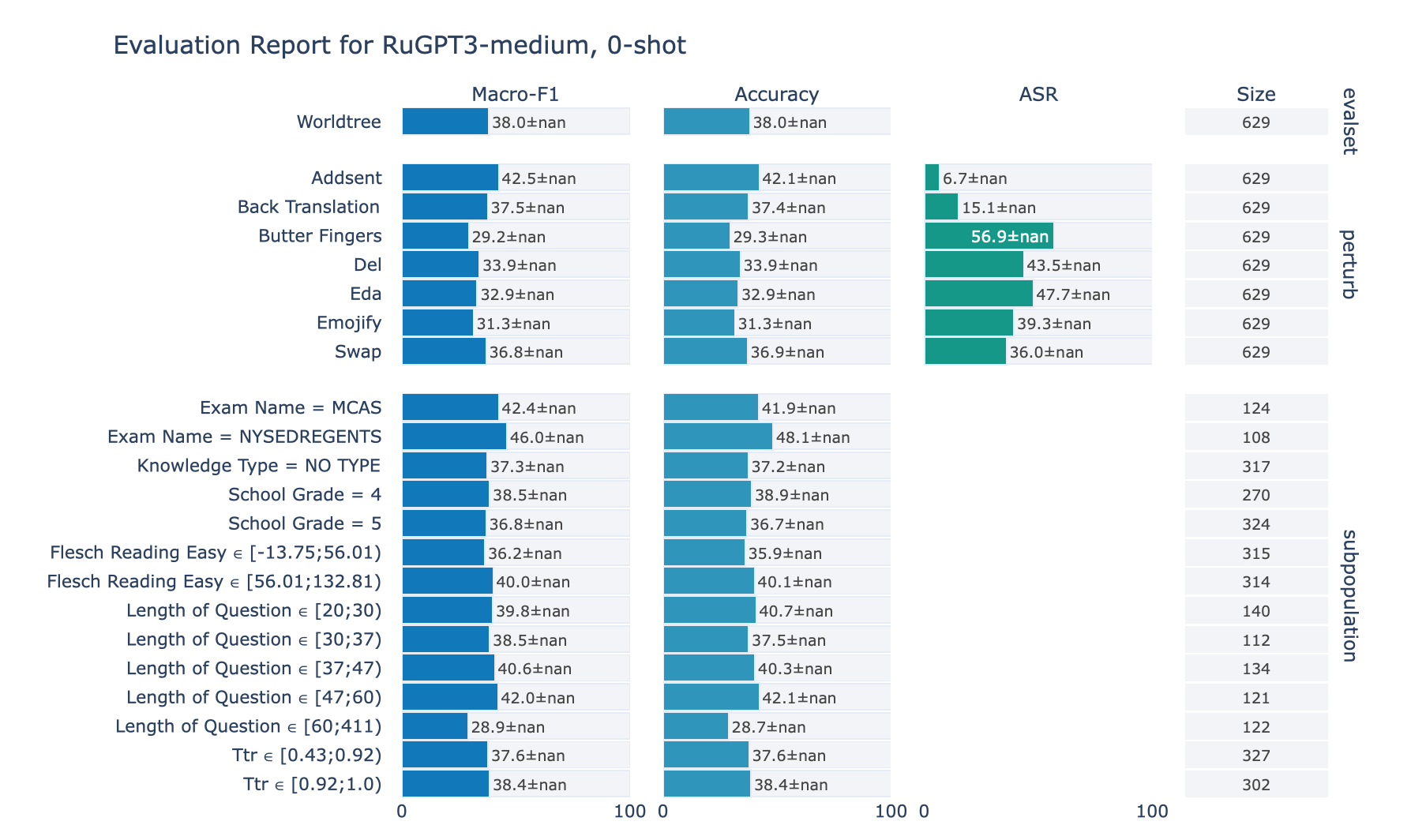
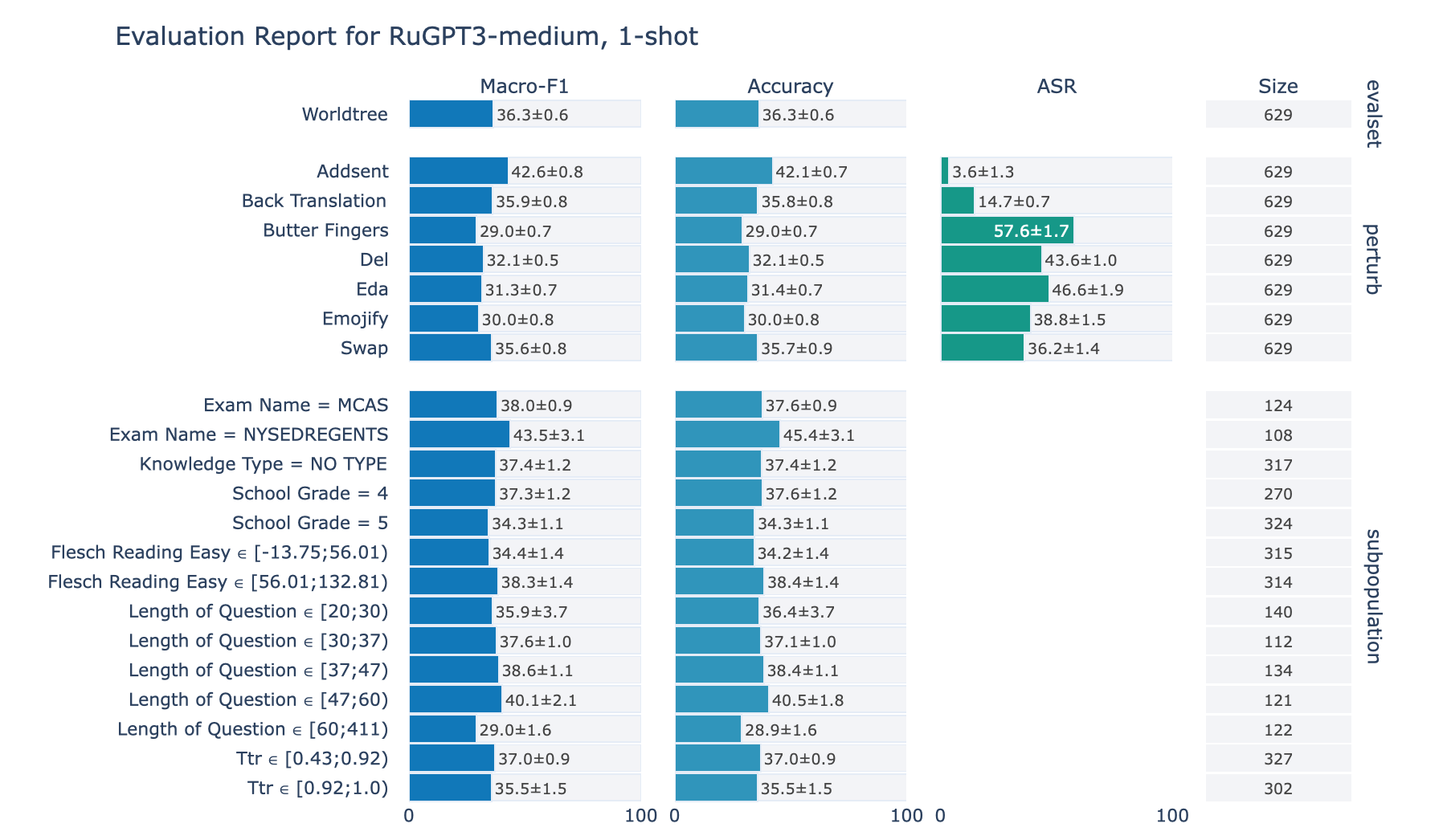
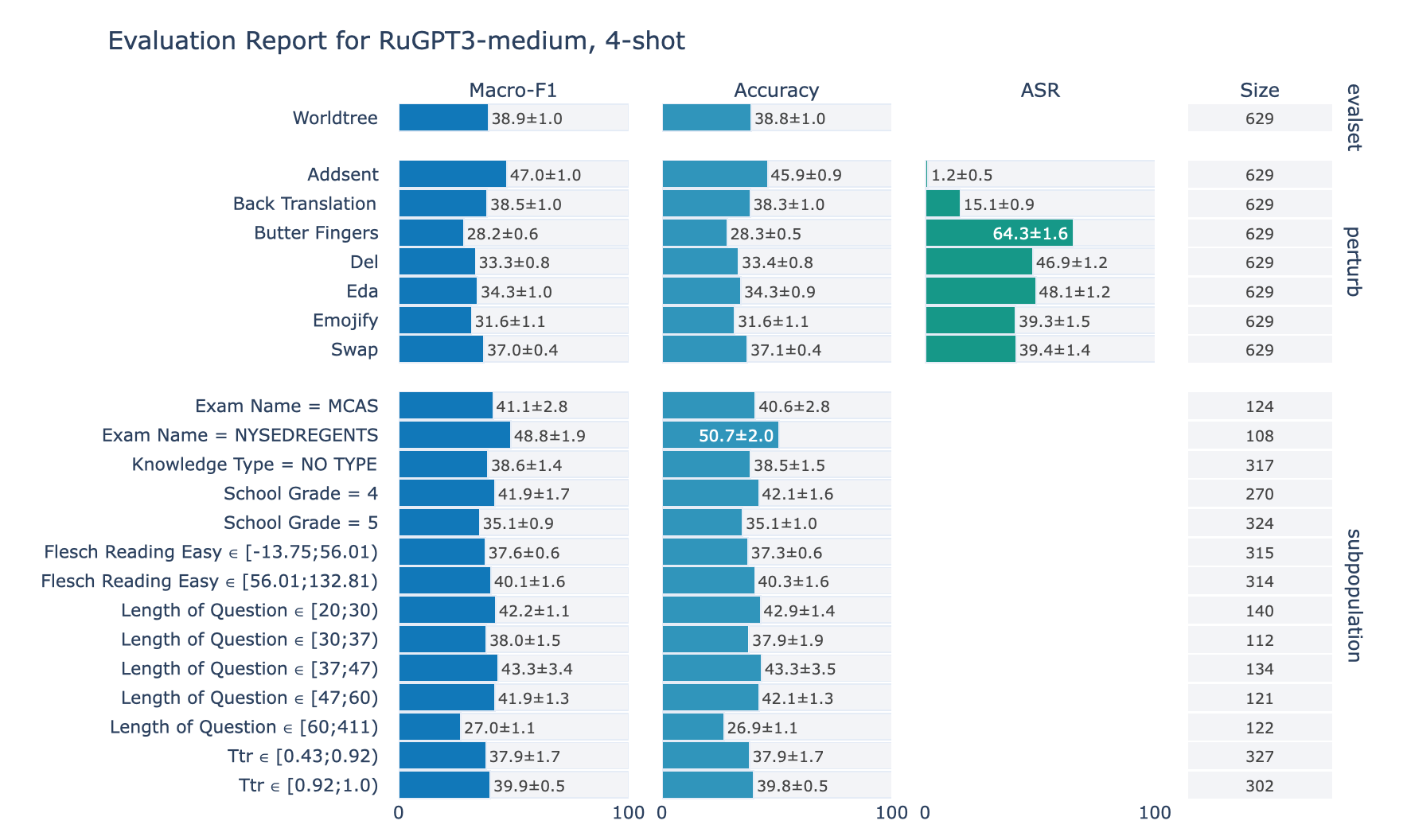
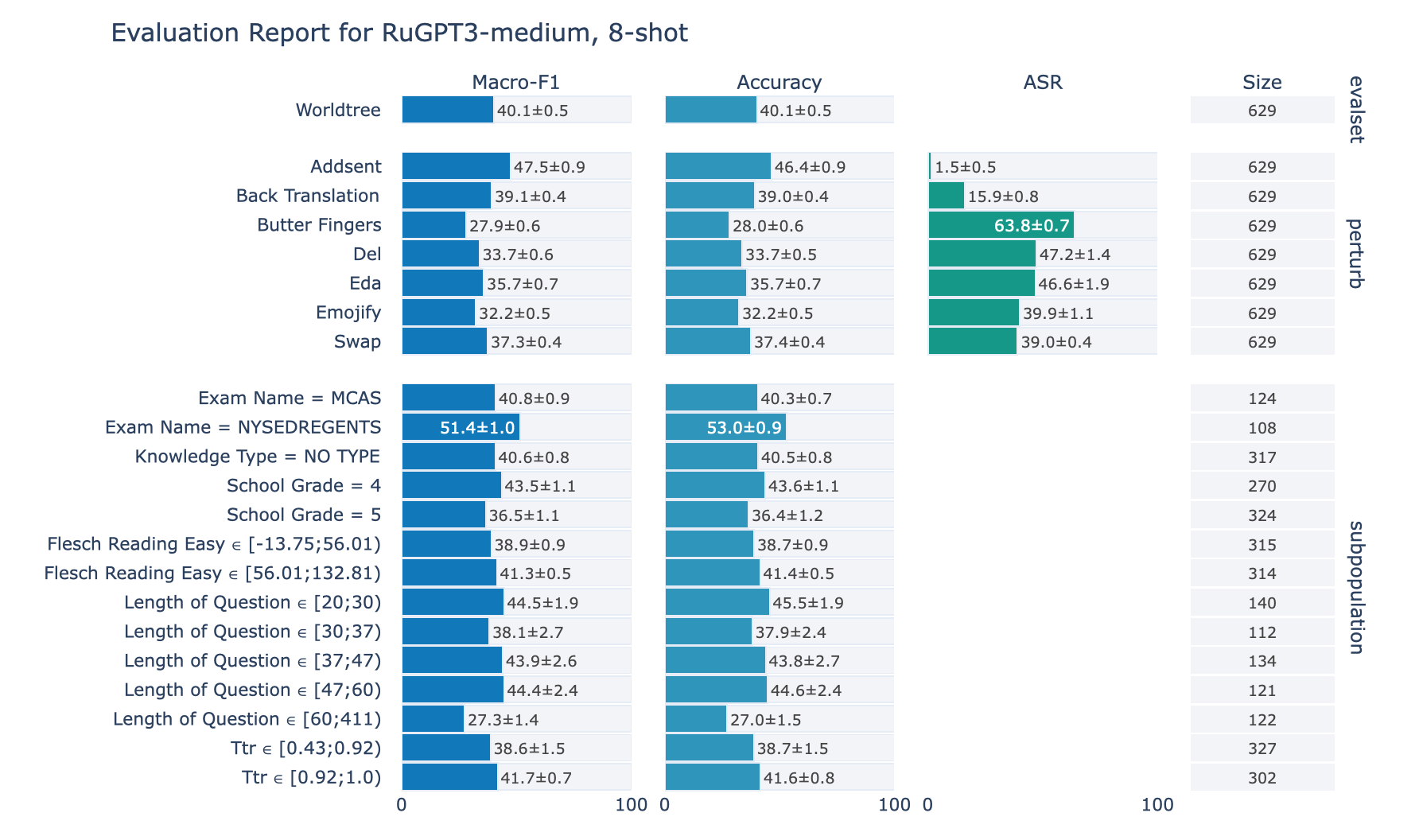
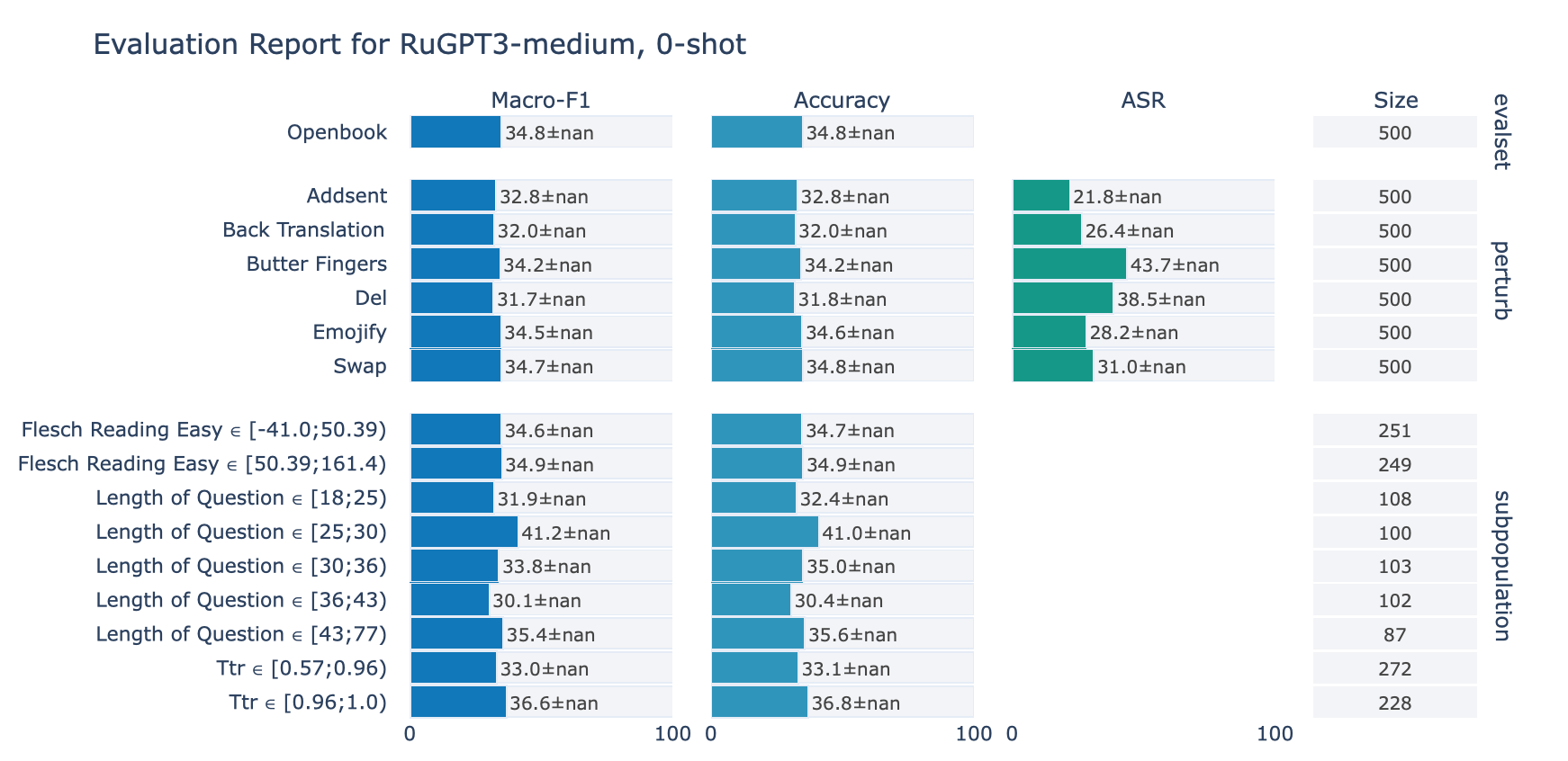
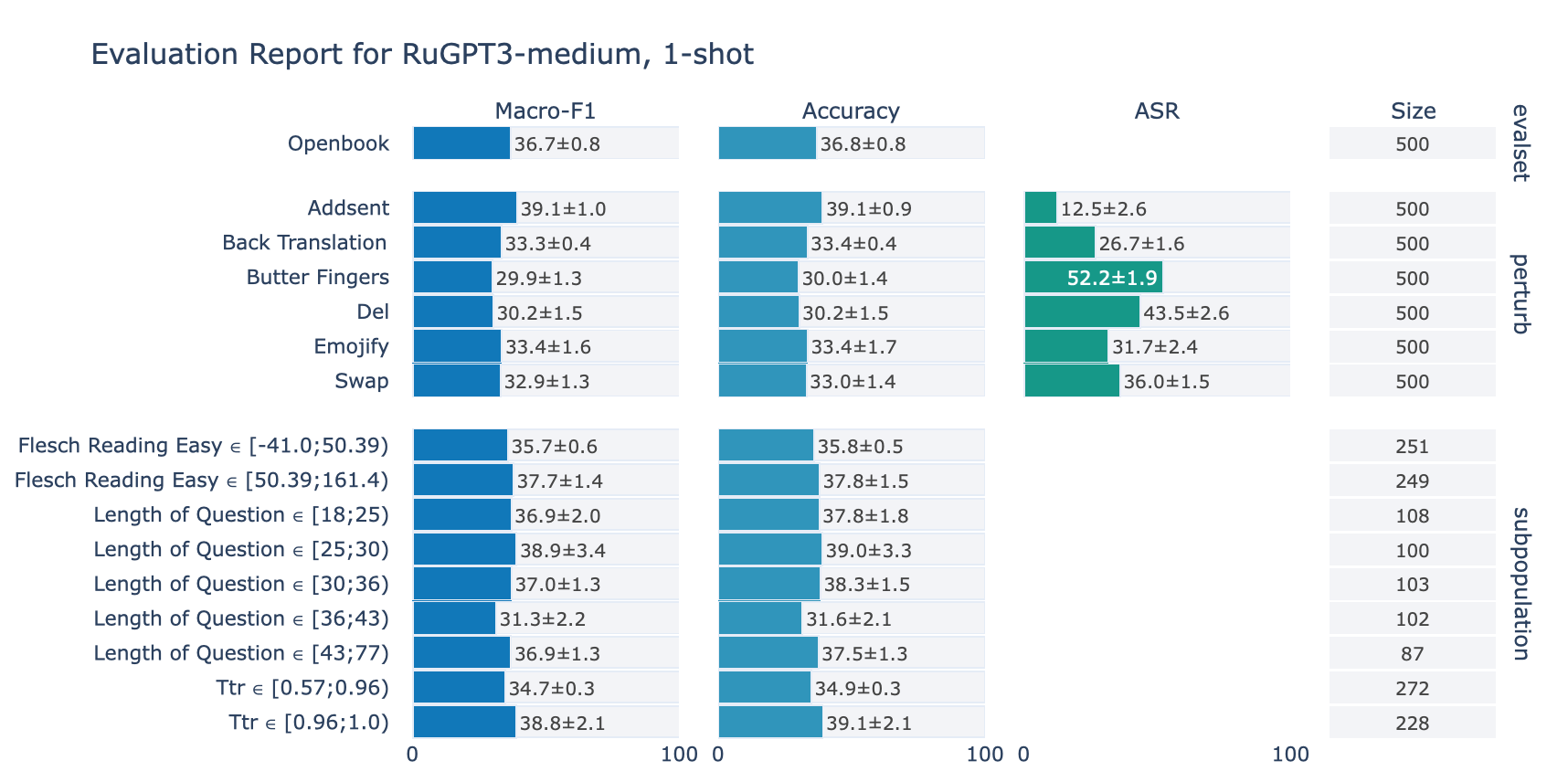
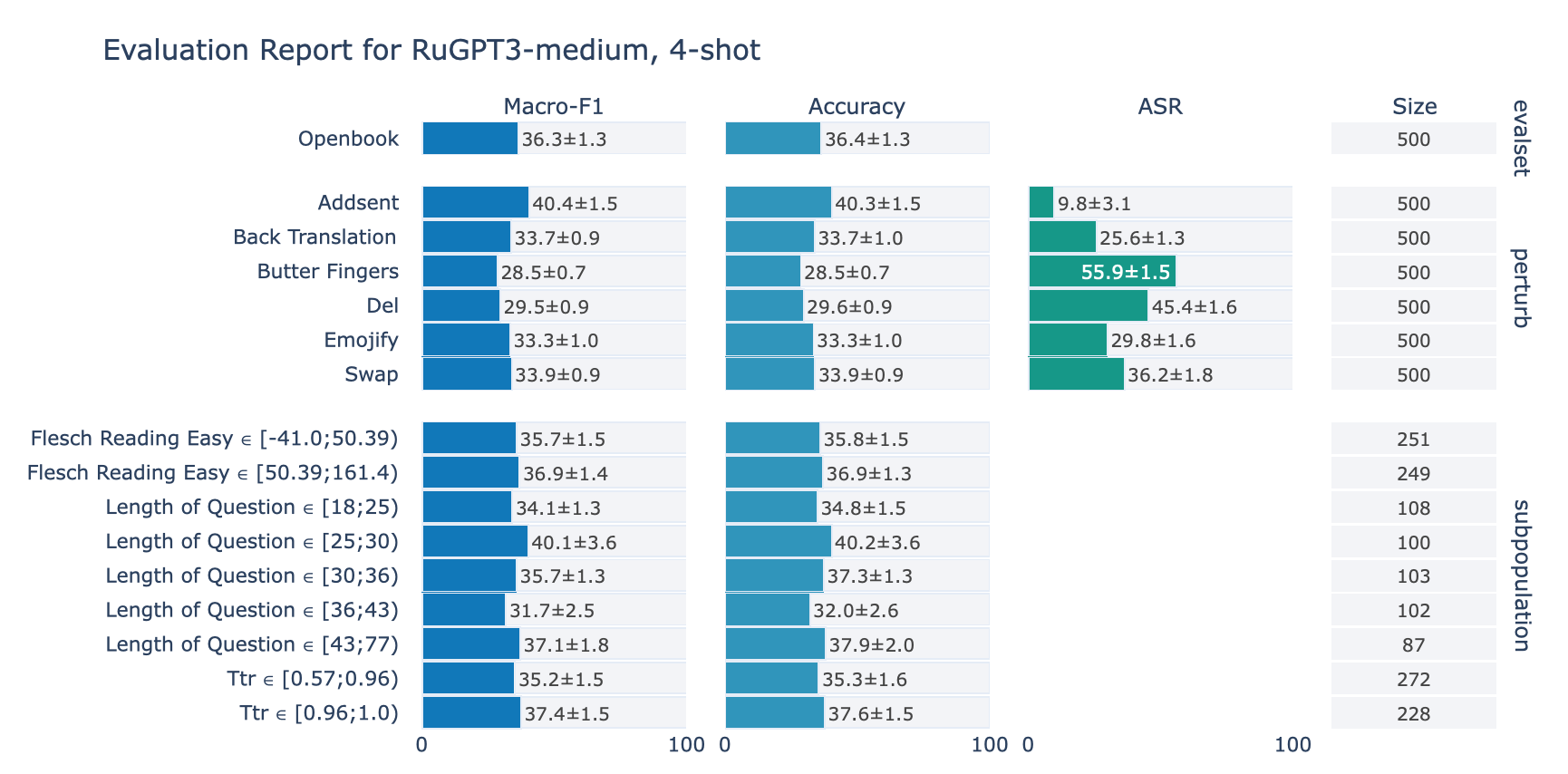
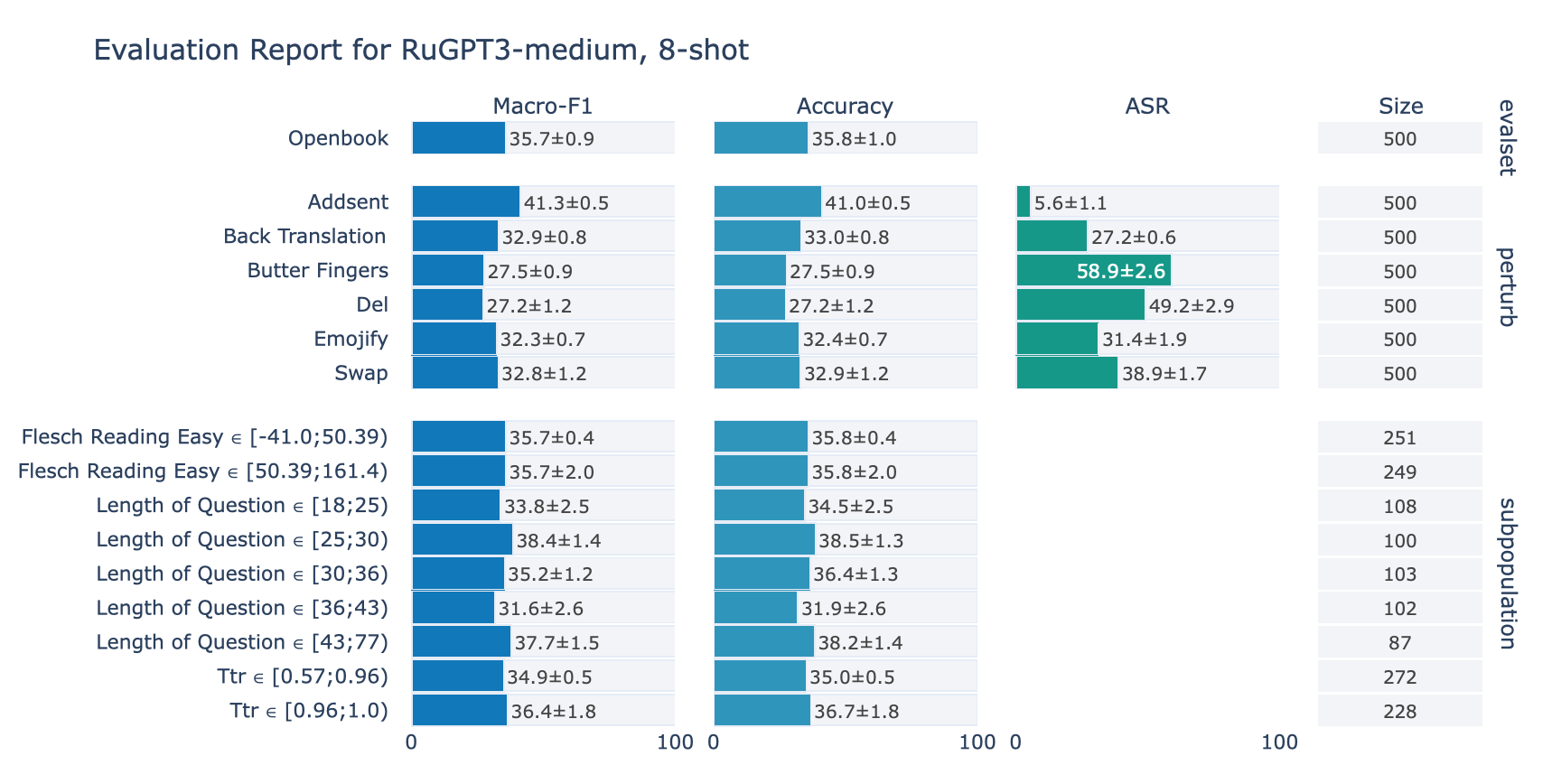
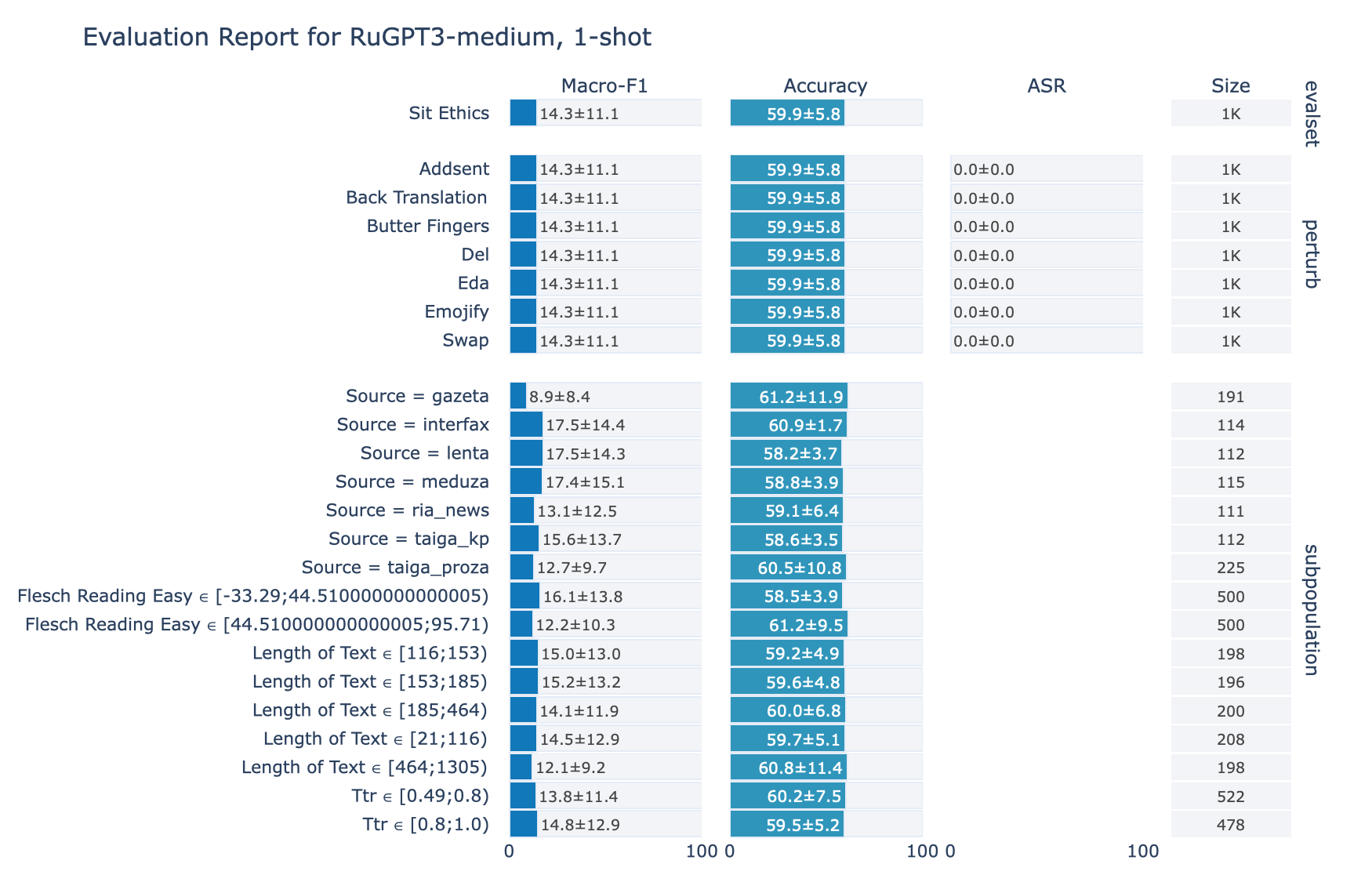
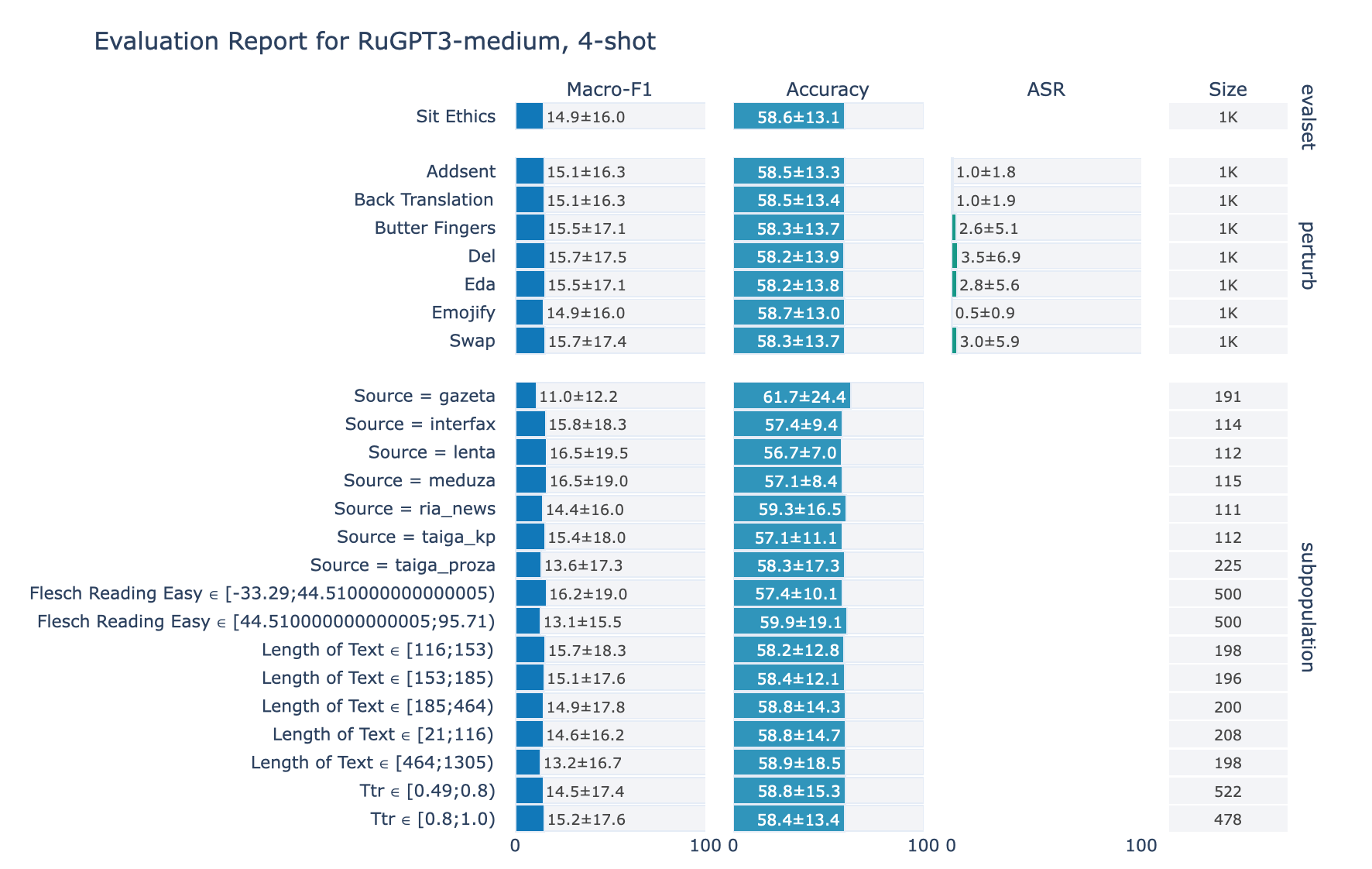
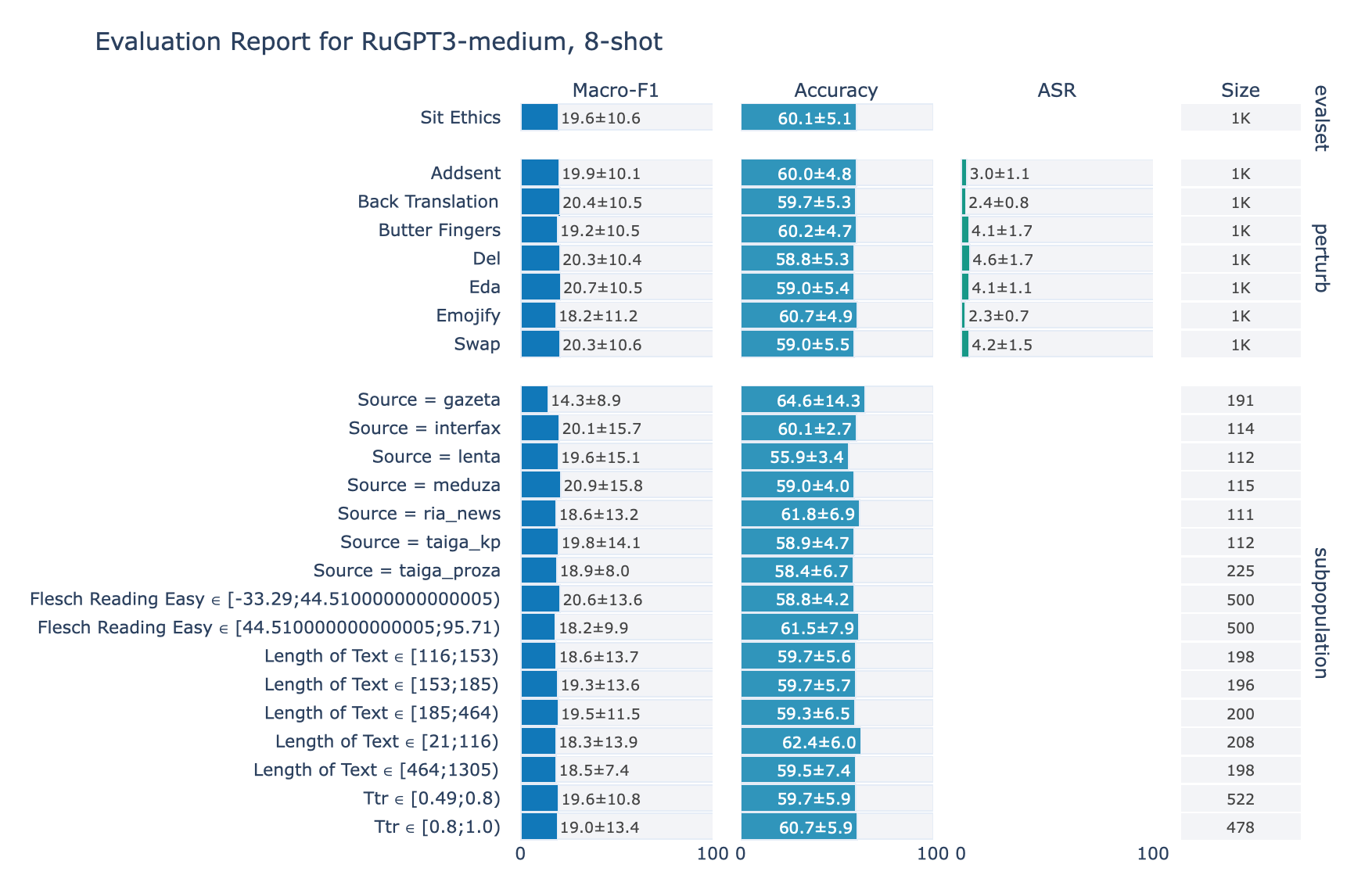
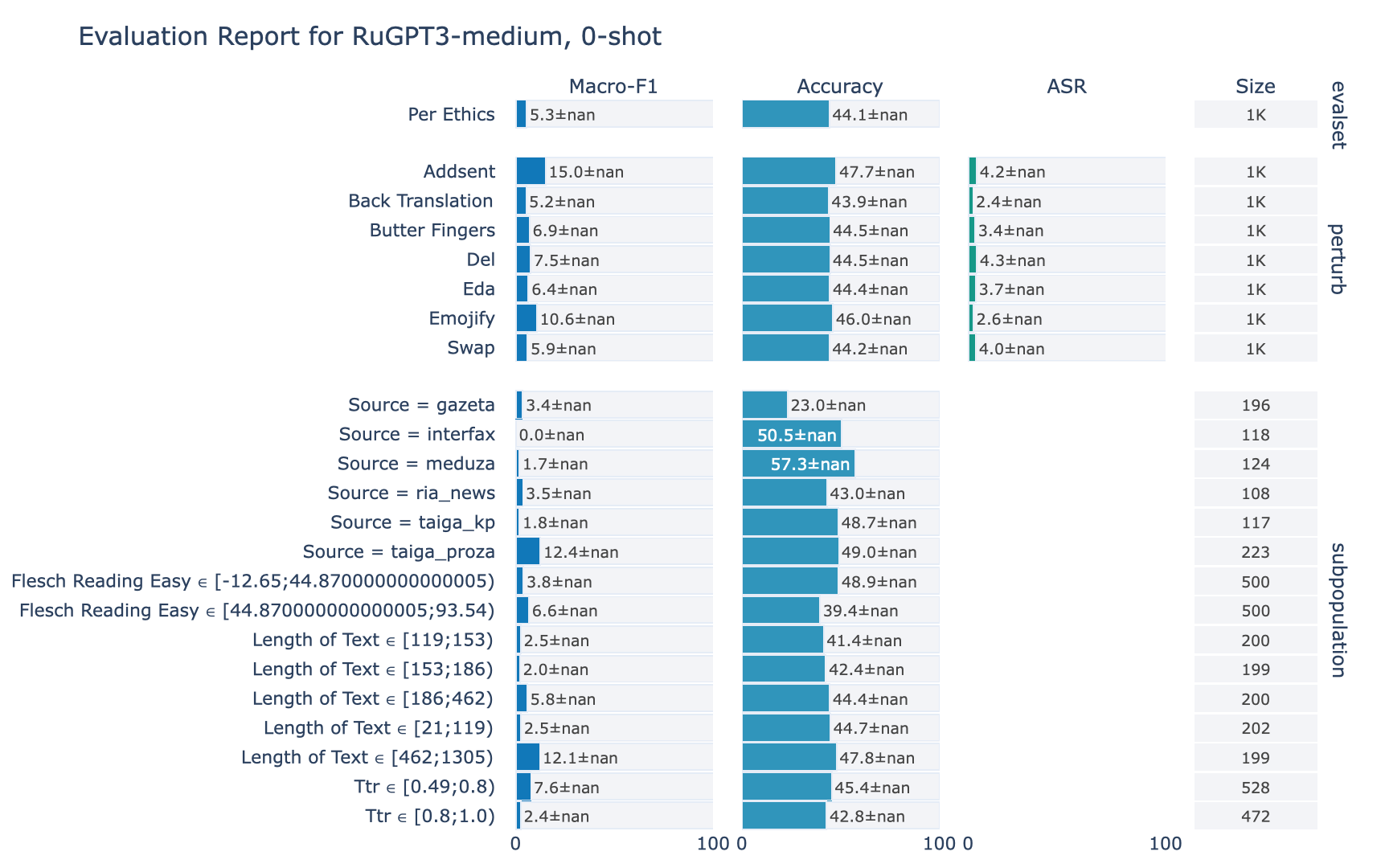
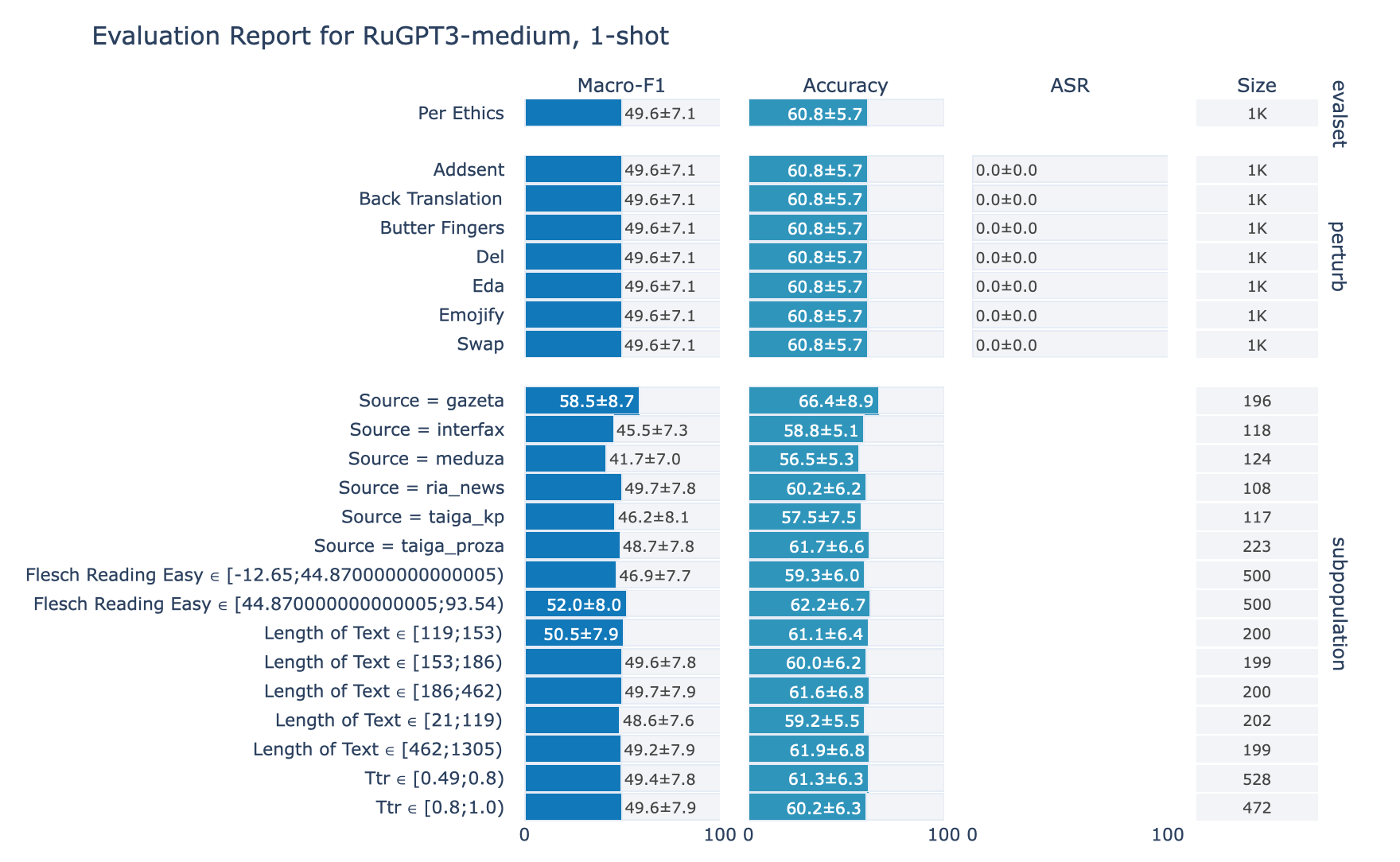
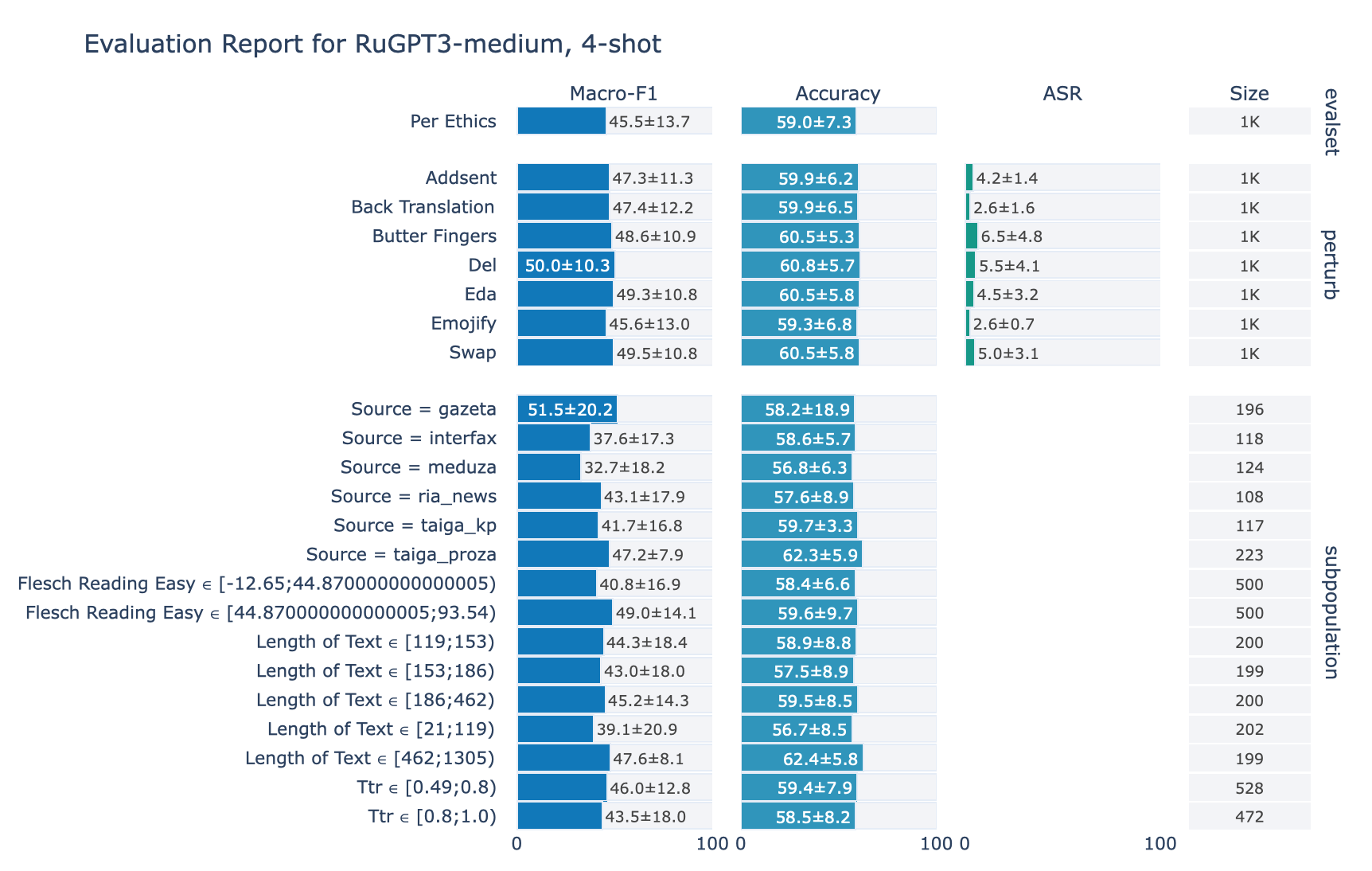
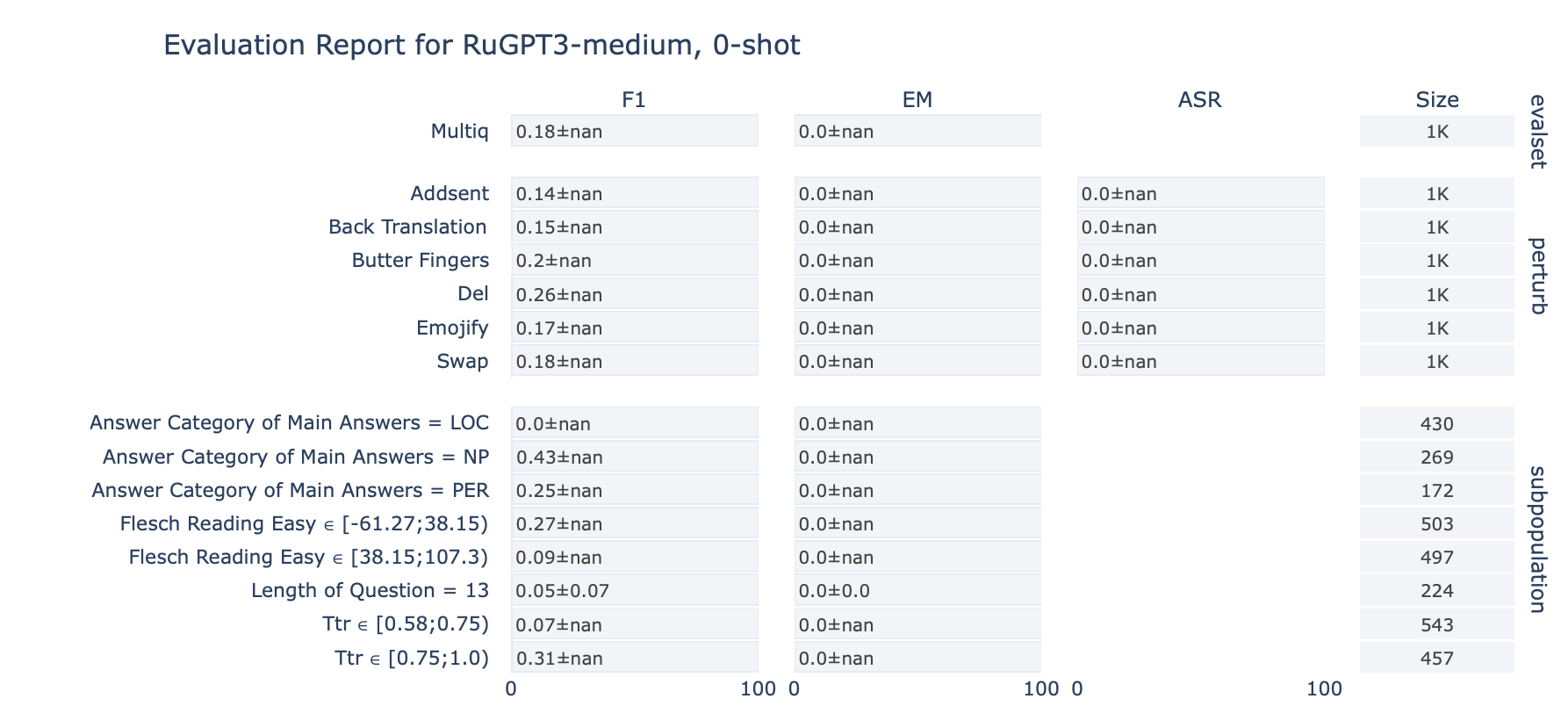
ruGPT-3 Medium
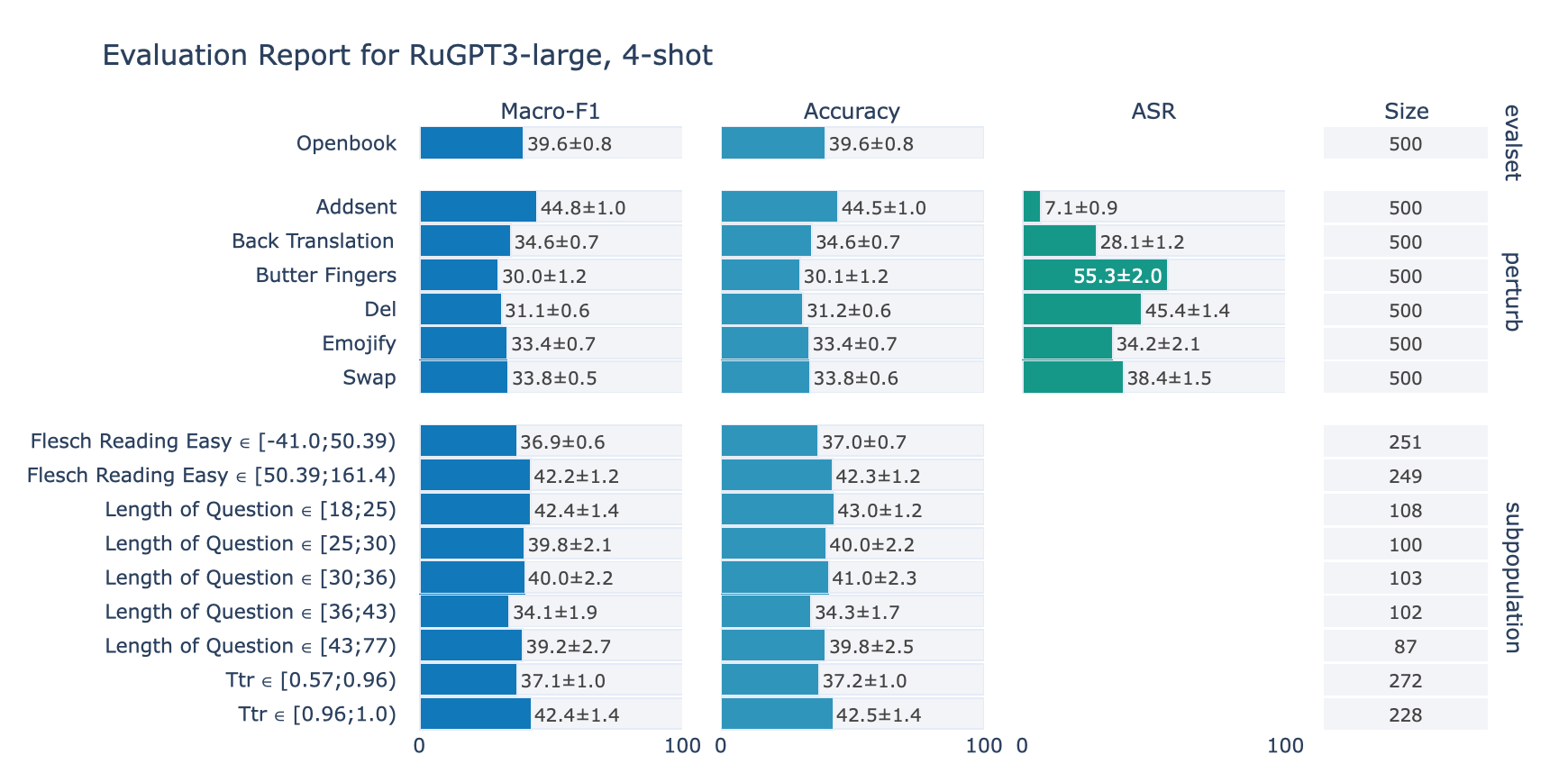
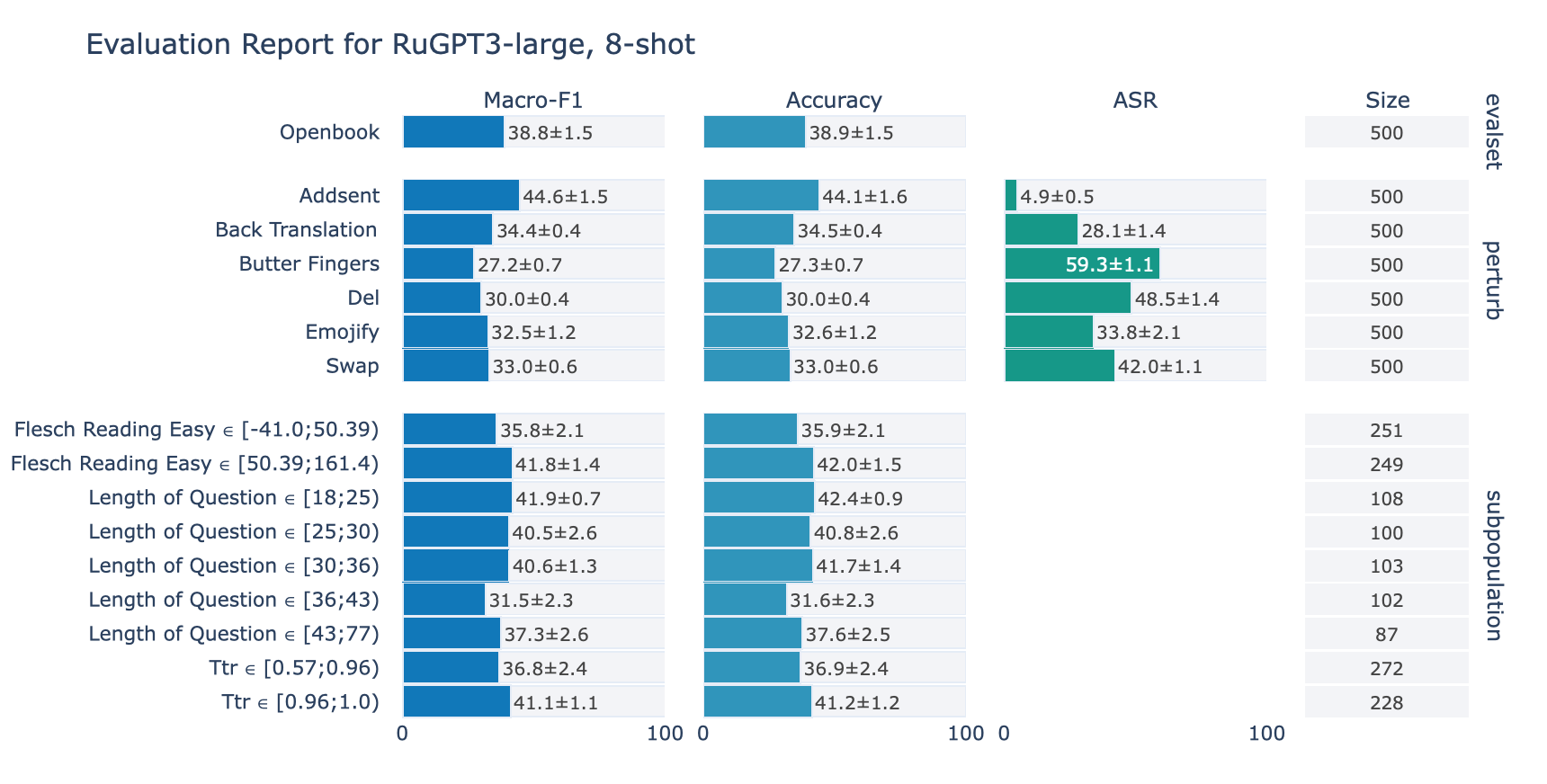
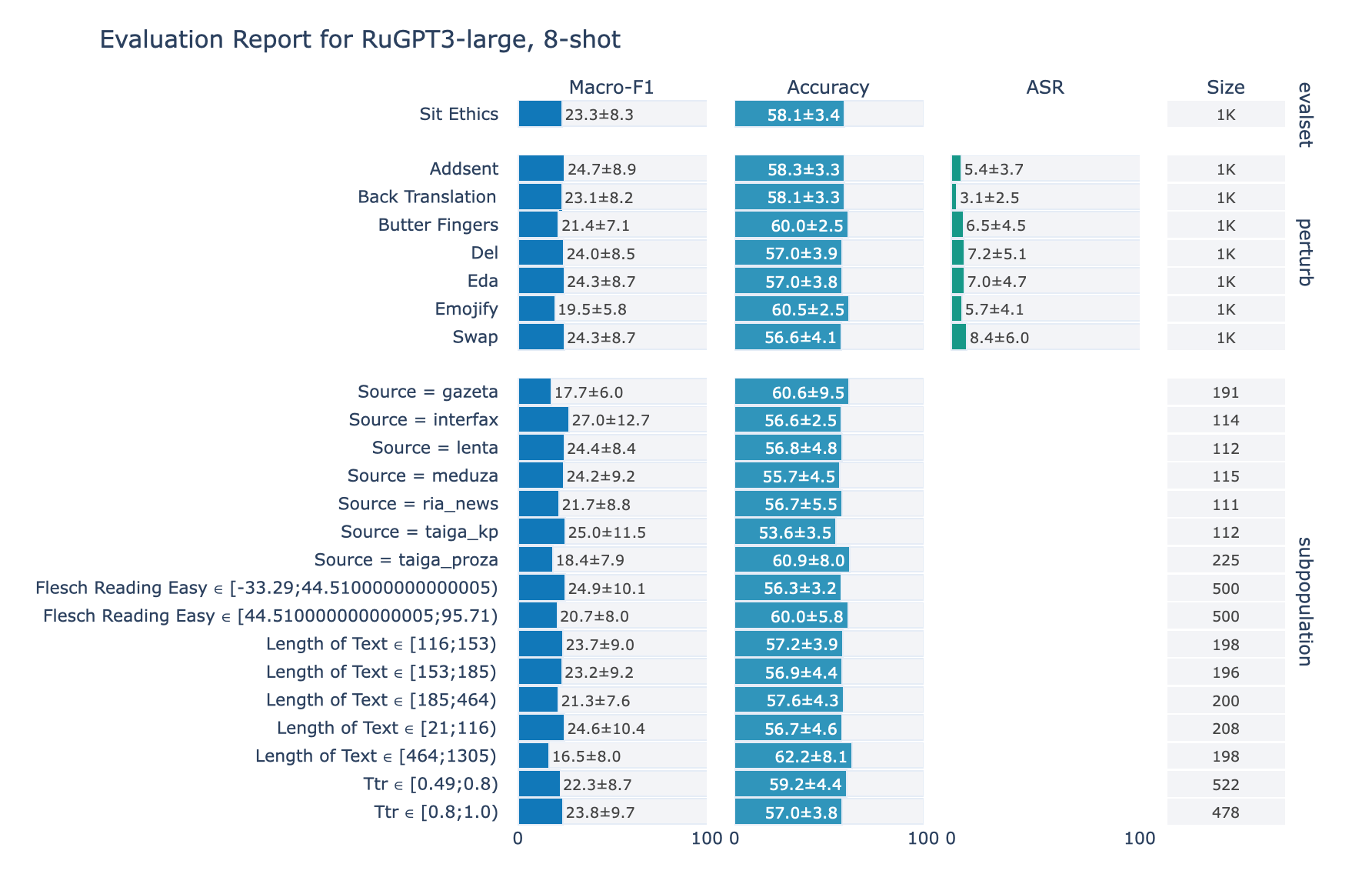
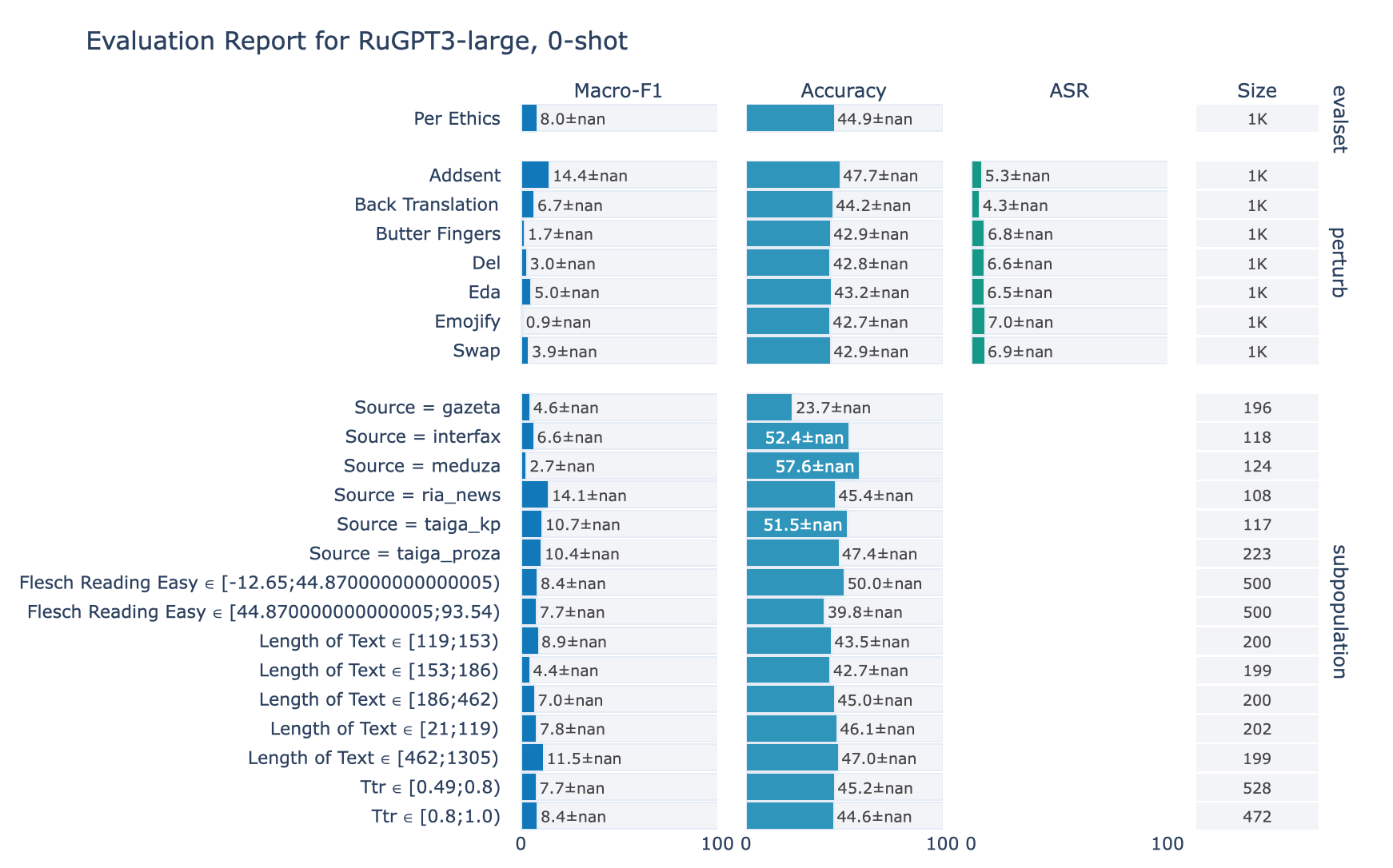
ruGPT-3 Large
ruGPT-3 Small
Winograd
RuWorldTree
RuOpenBookQA
Ethics
1
Ethics
2
MultiQ
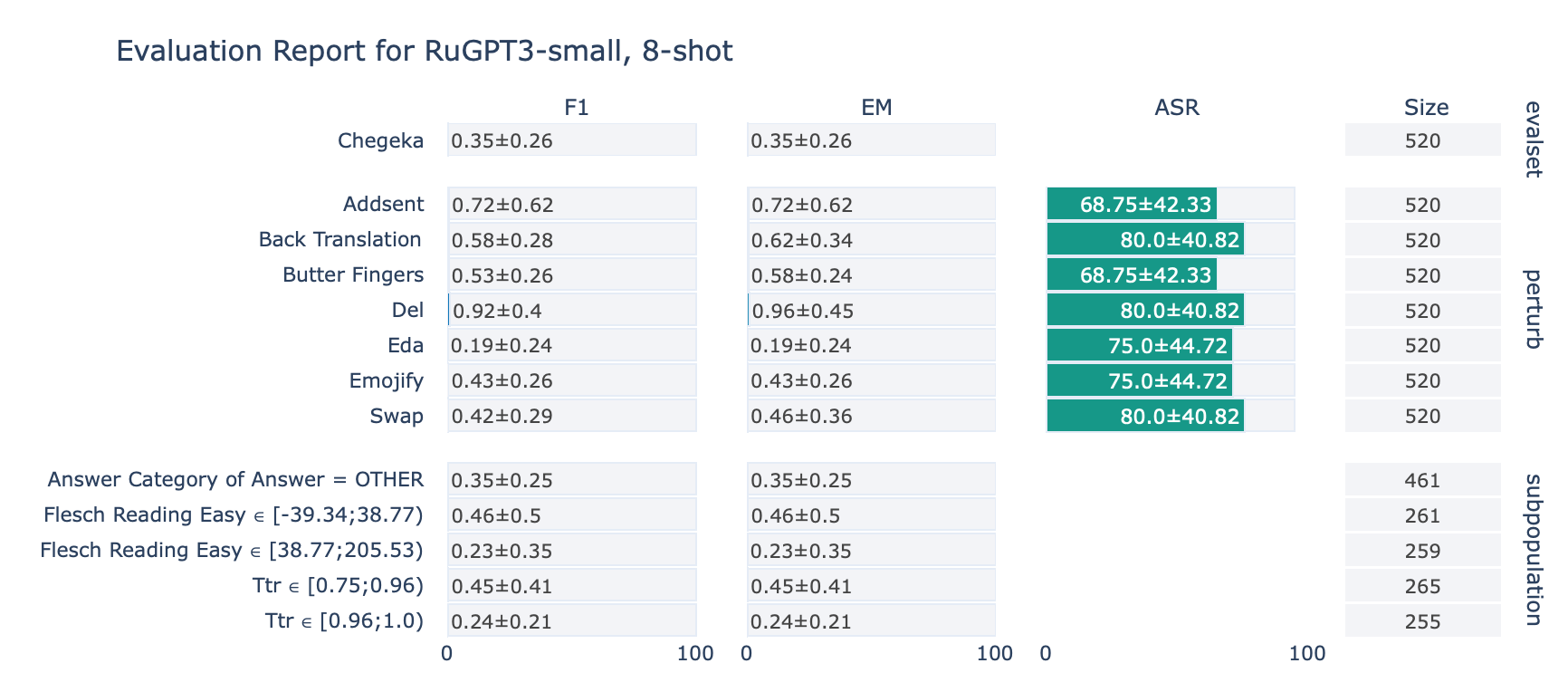
CheGeKa
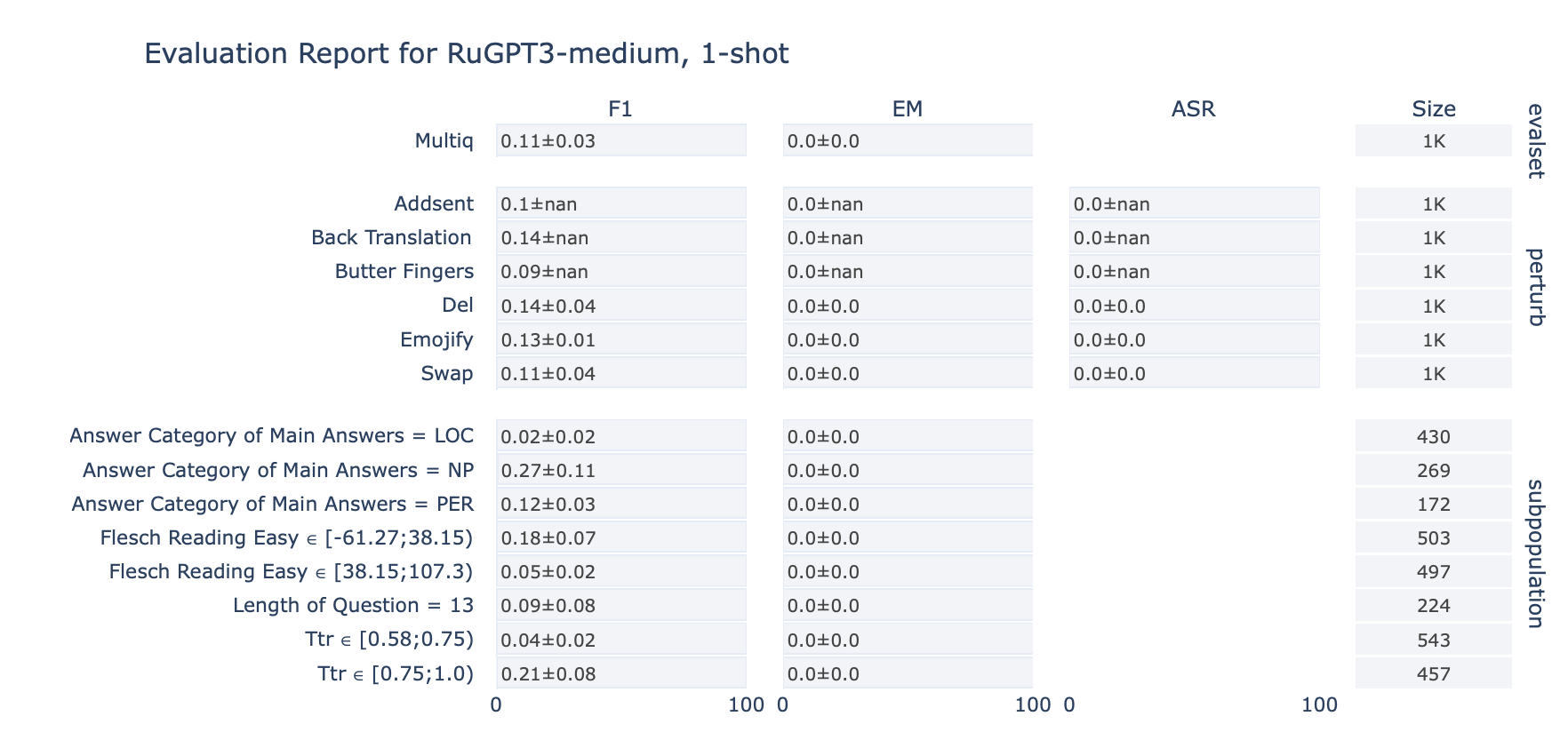
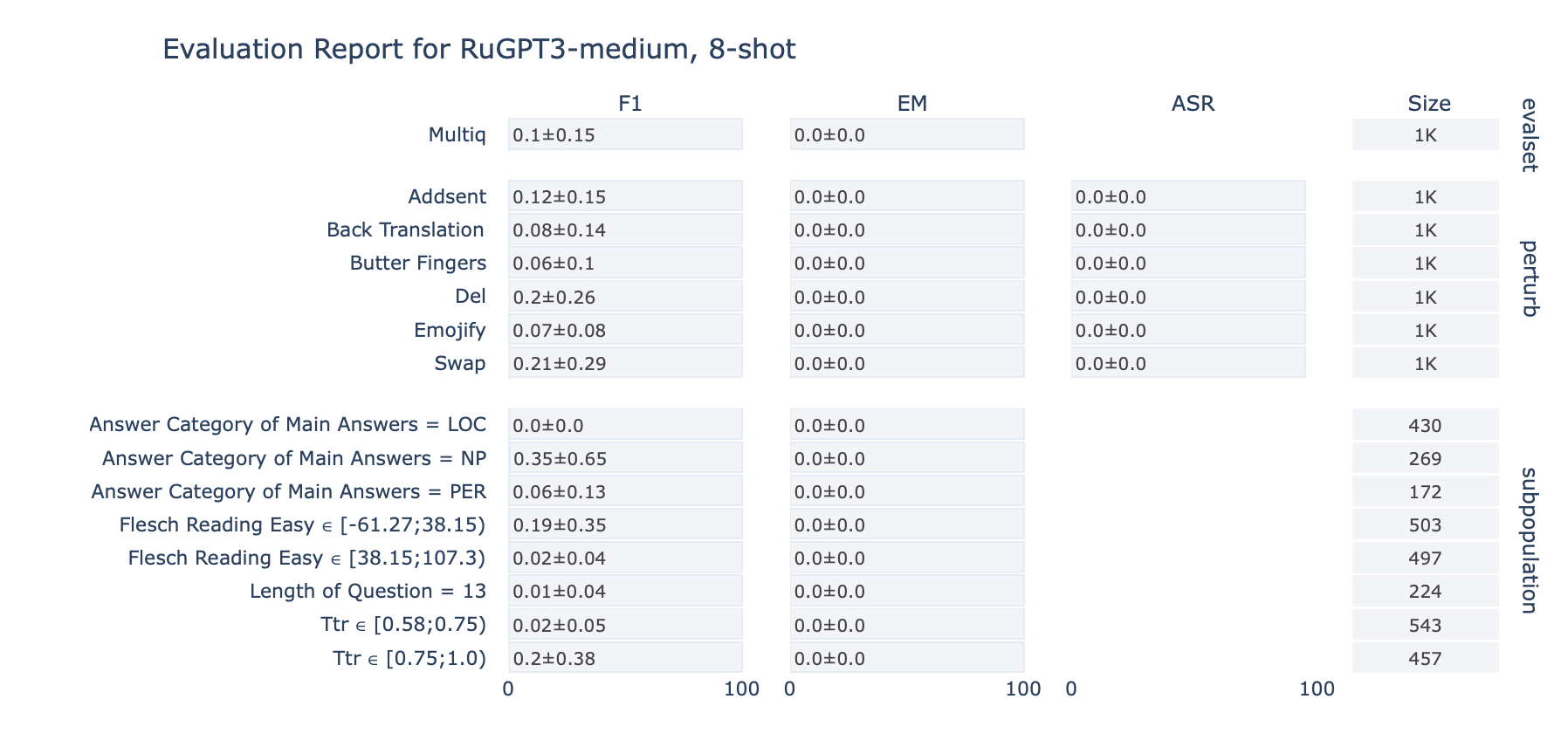
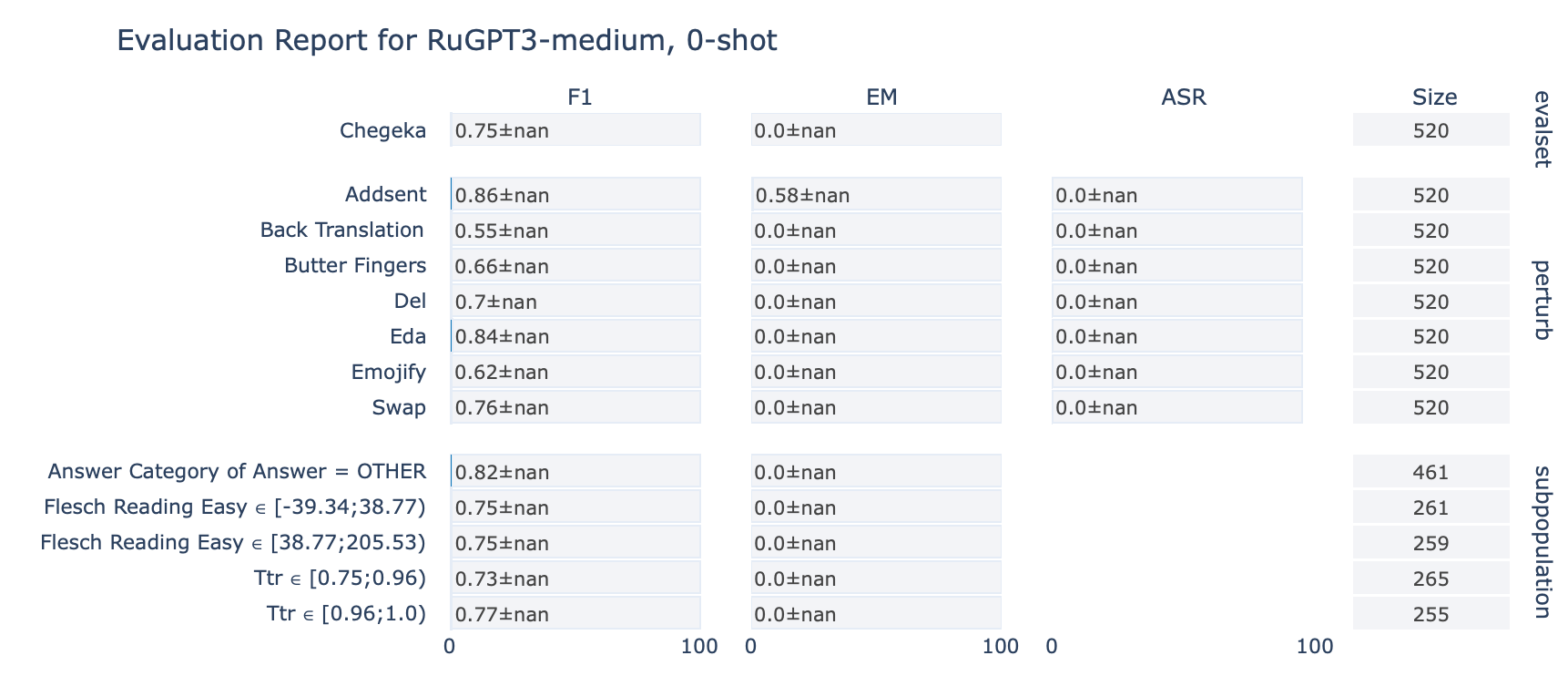
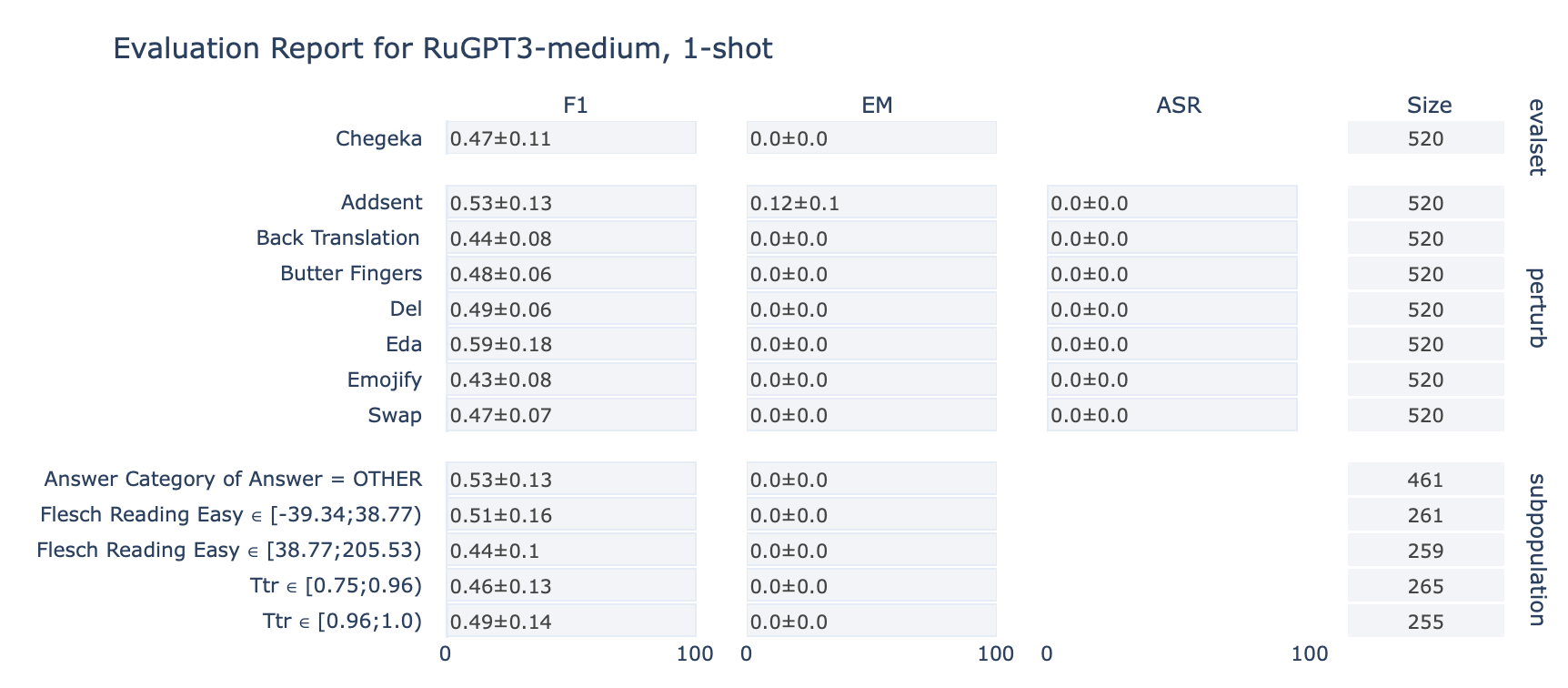
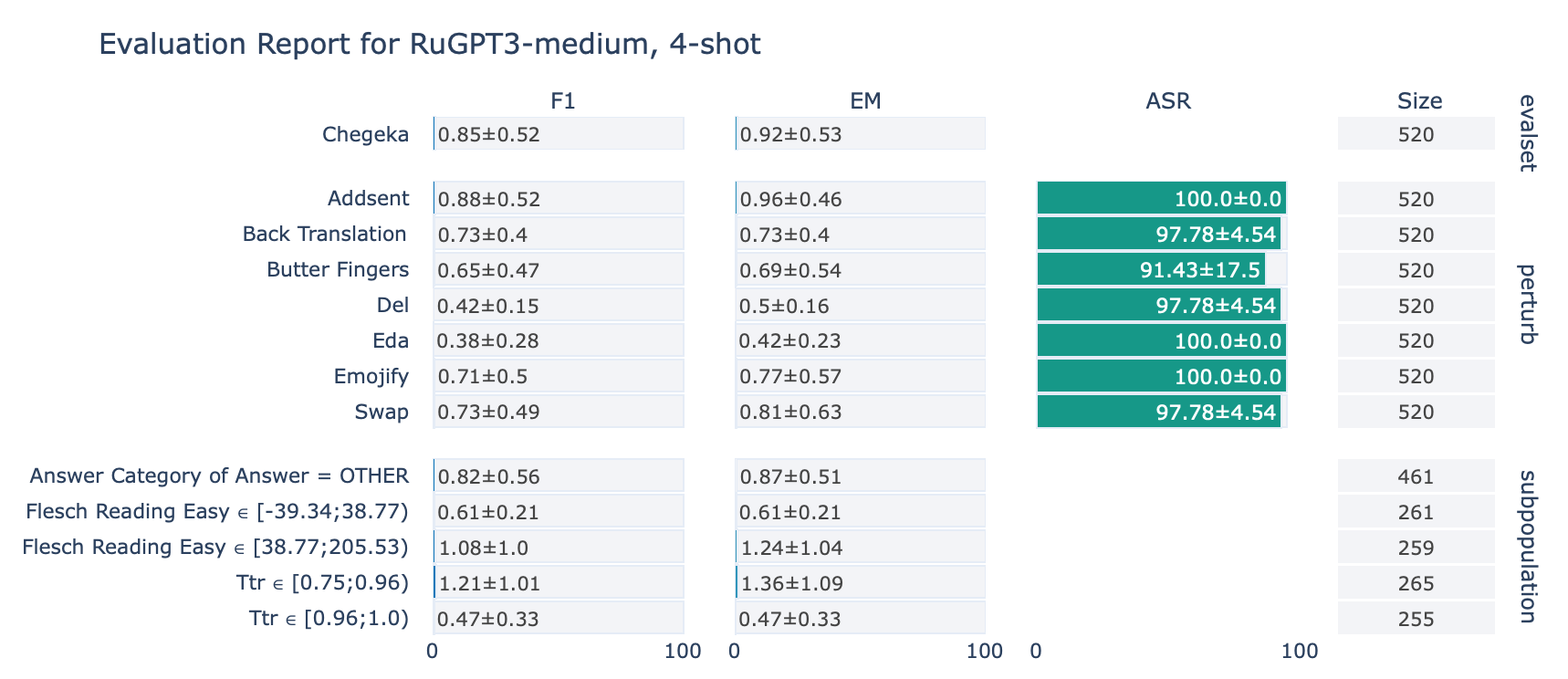
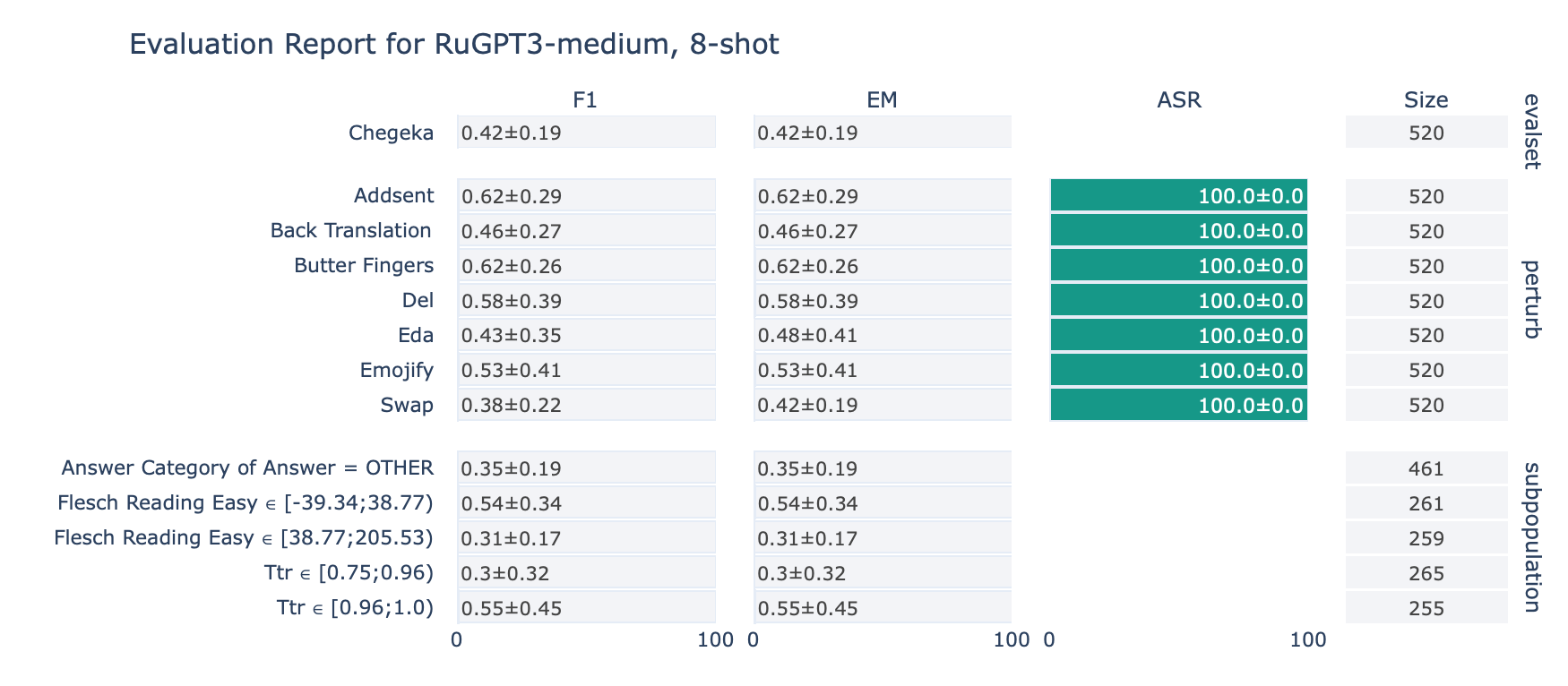
ruGPT-3 Medium
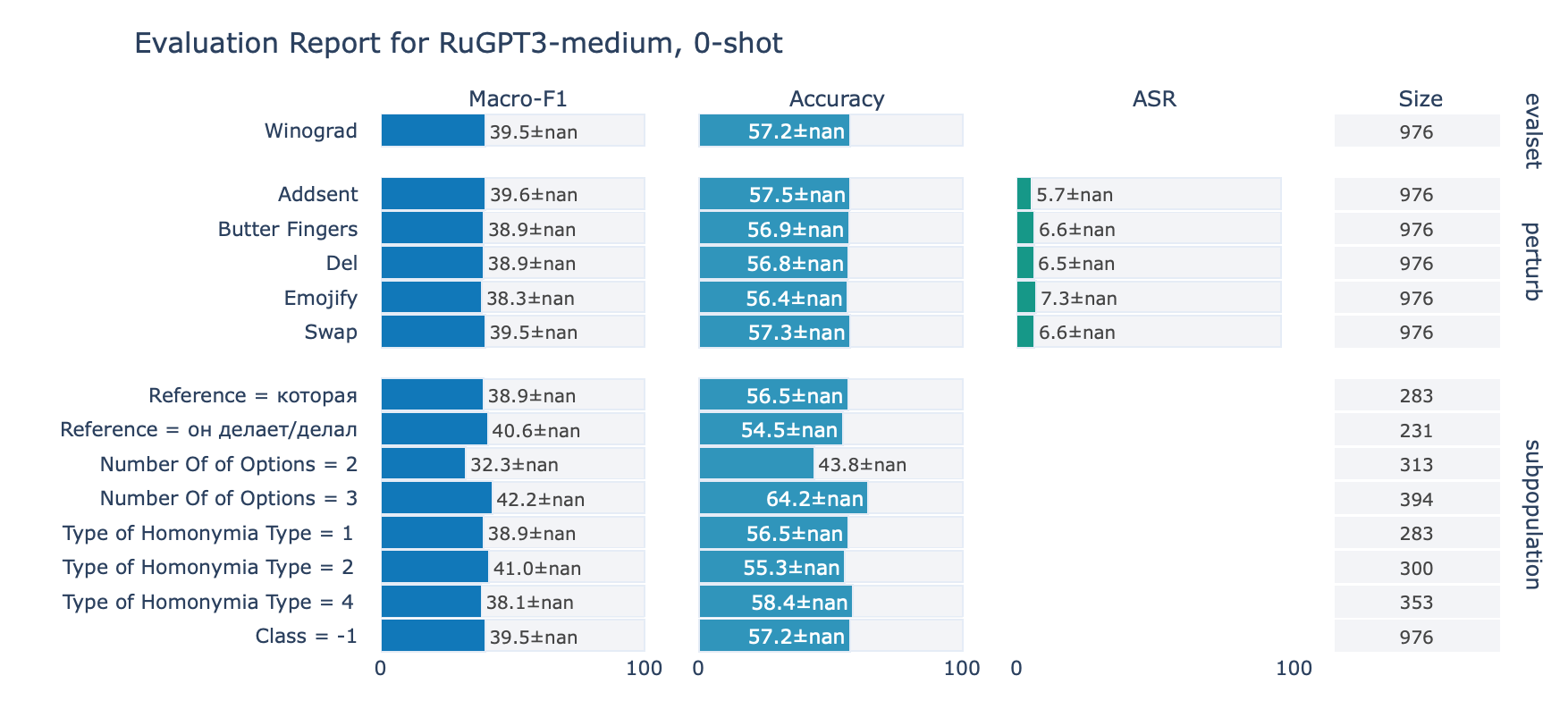
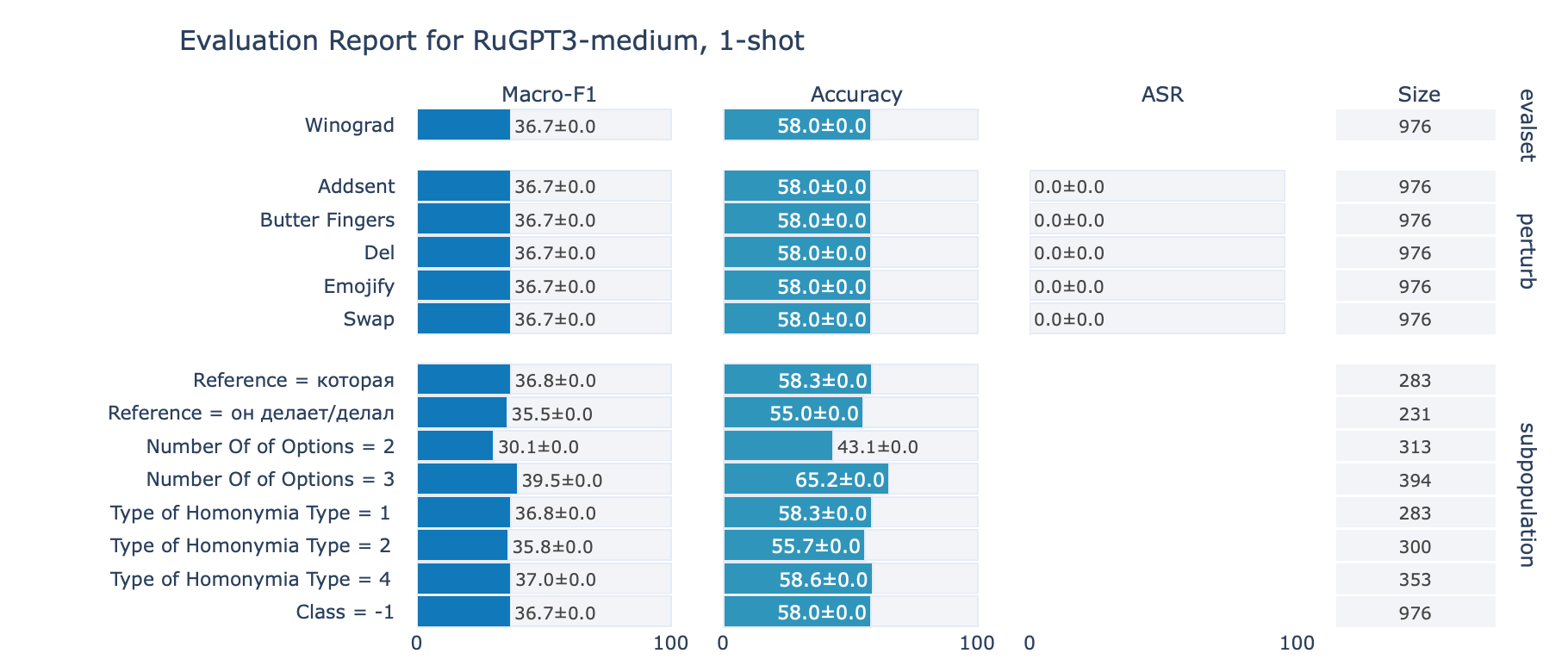
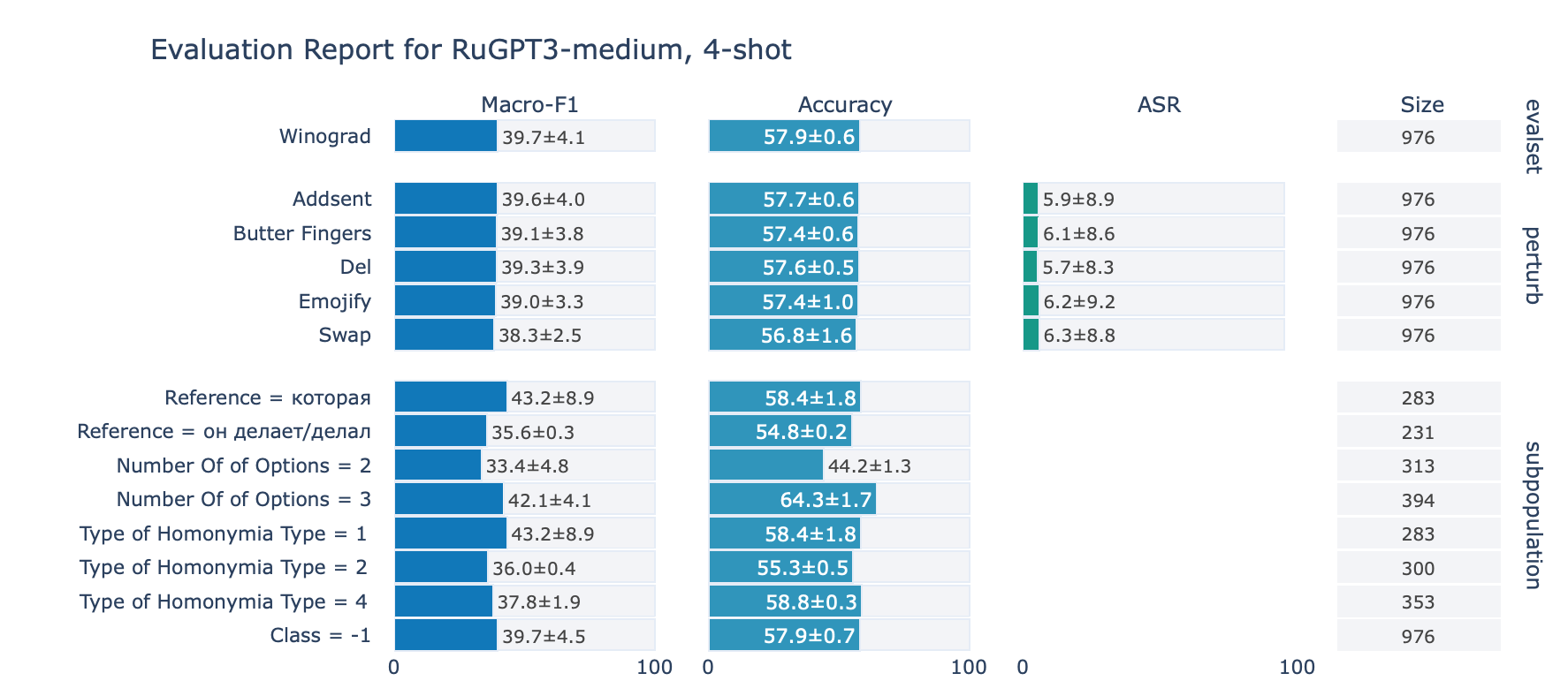
Winograd
RuWorldTree
RuOpenBookQA
Ethics
1
Ethics
2
MultiQ
CheGeKa
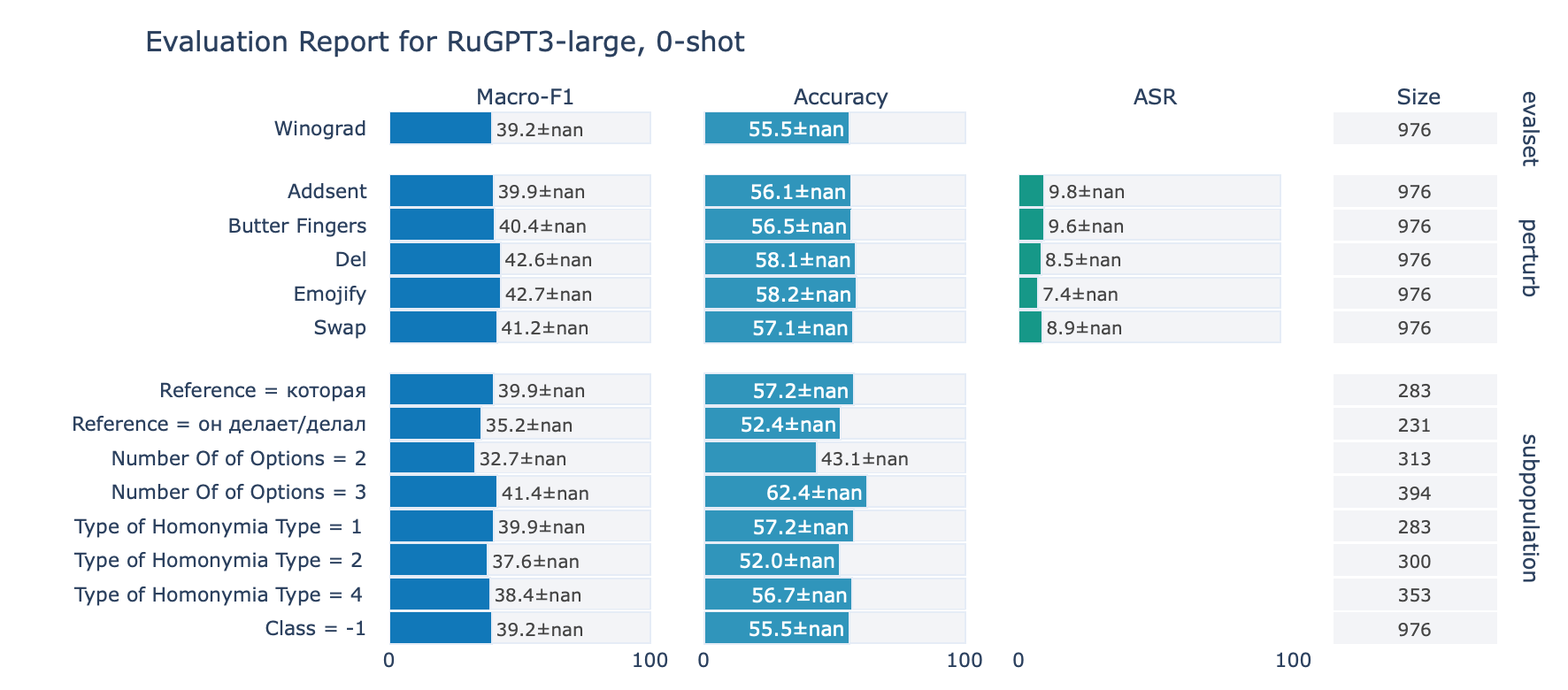
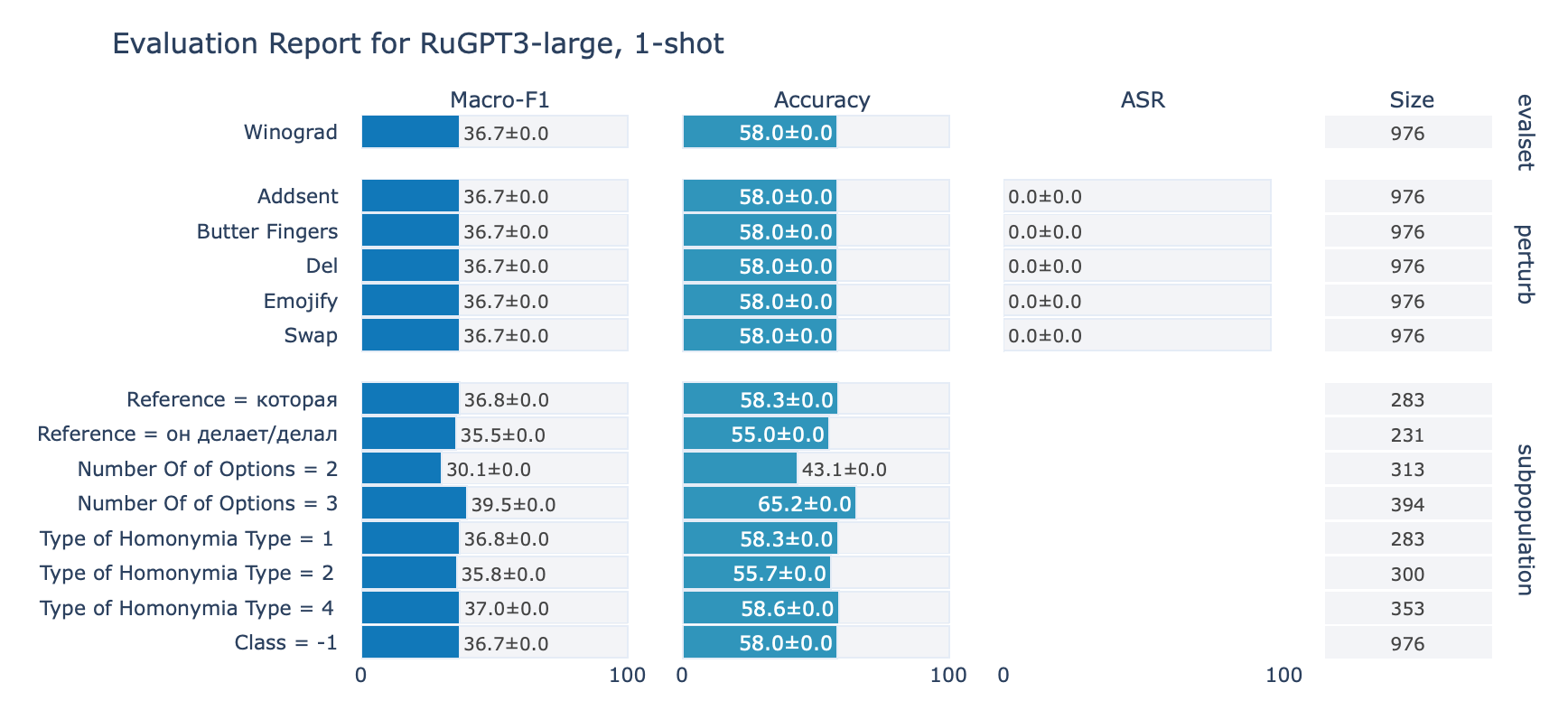
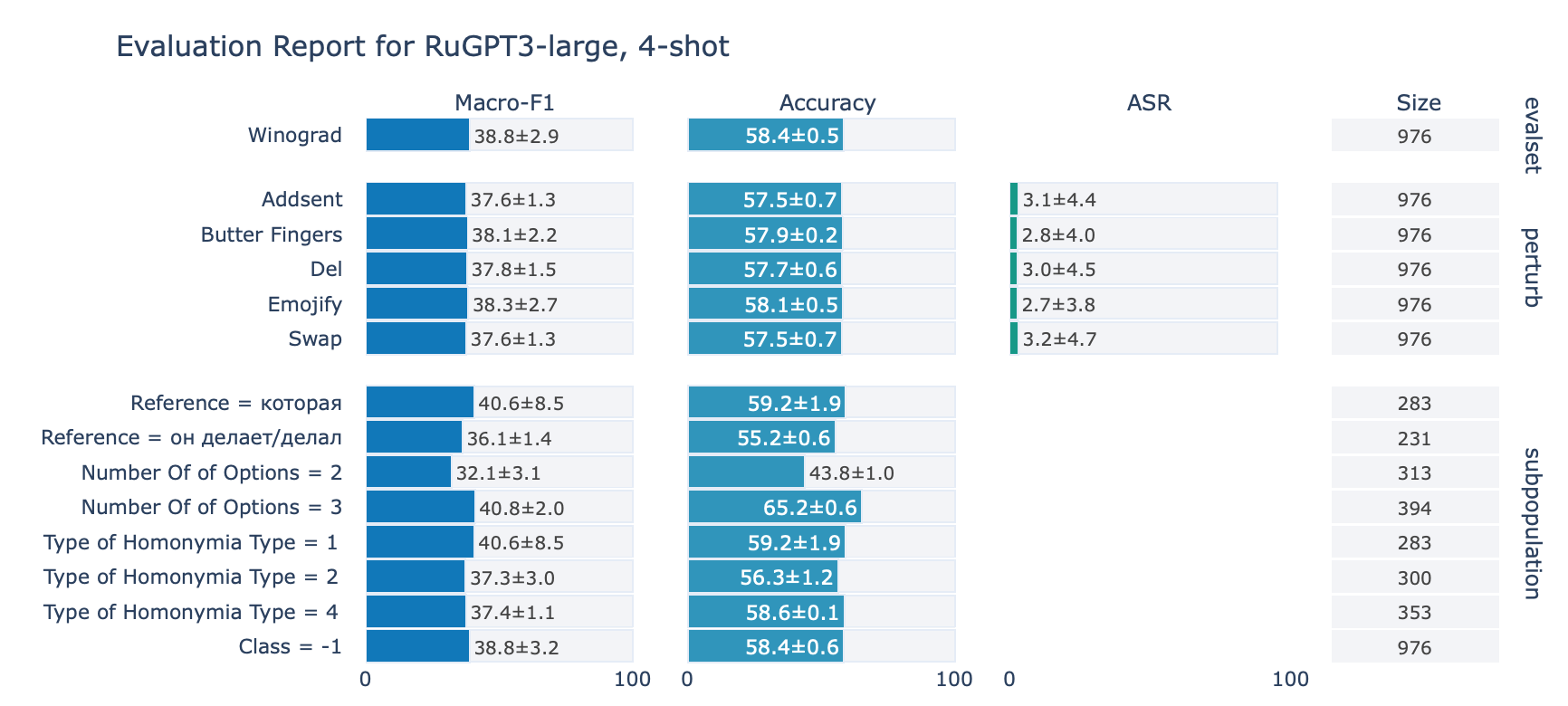
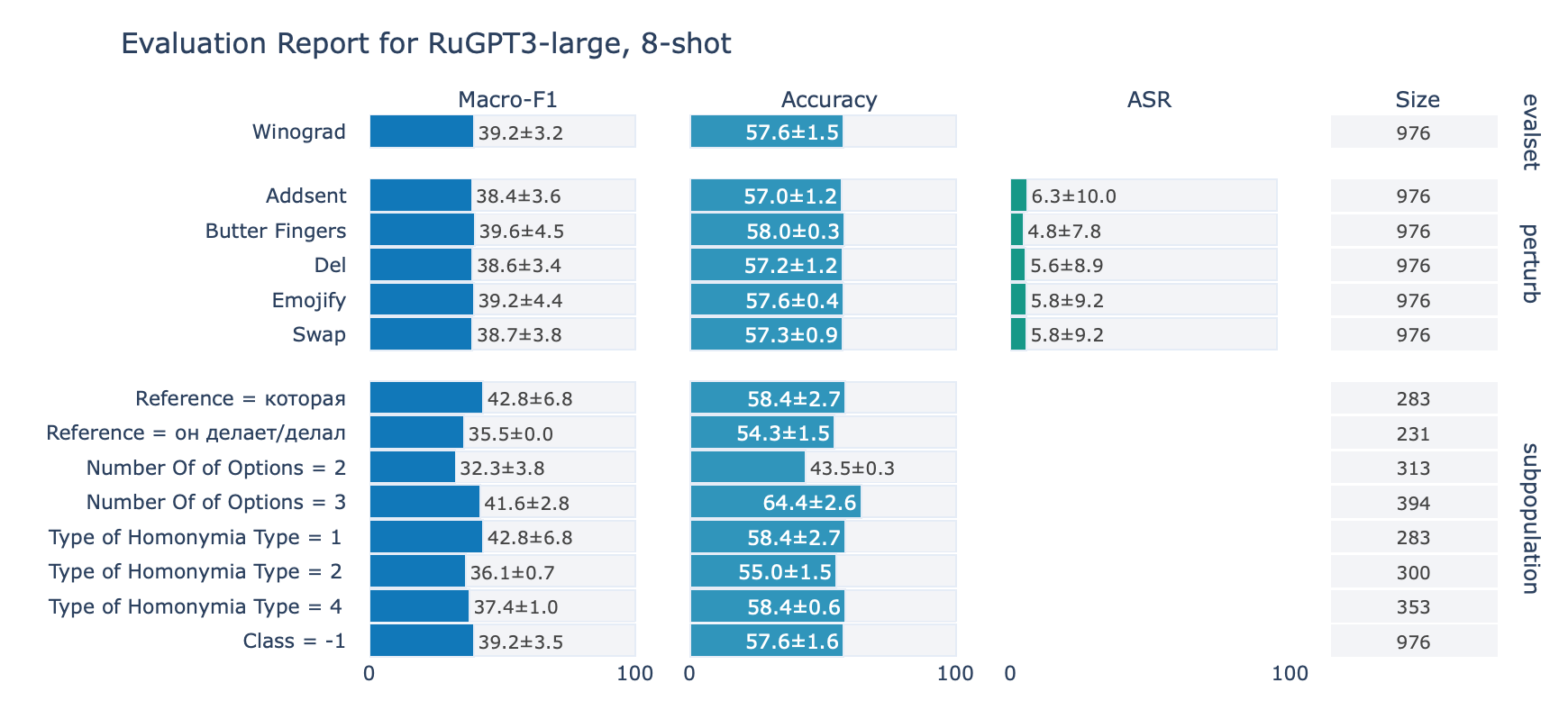
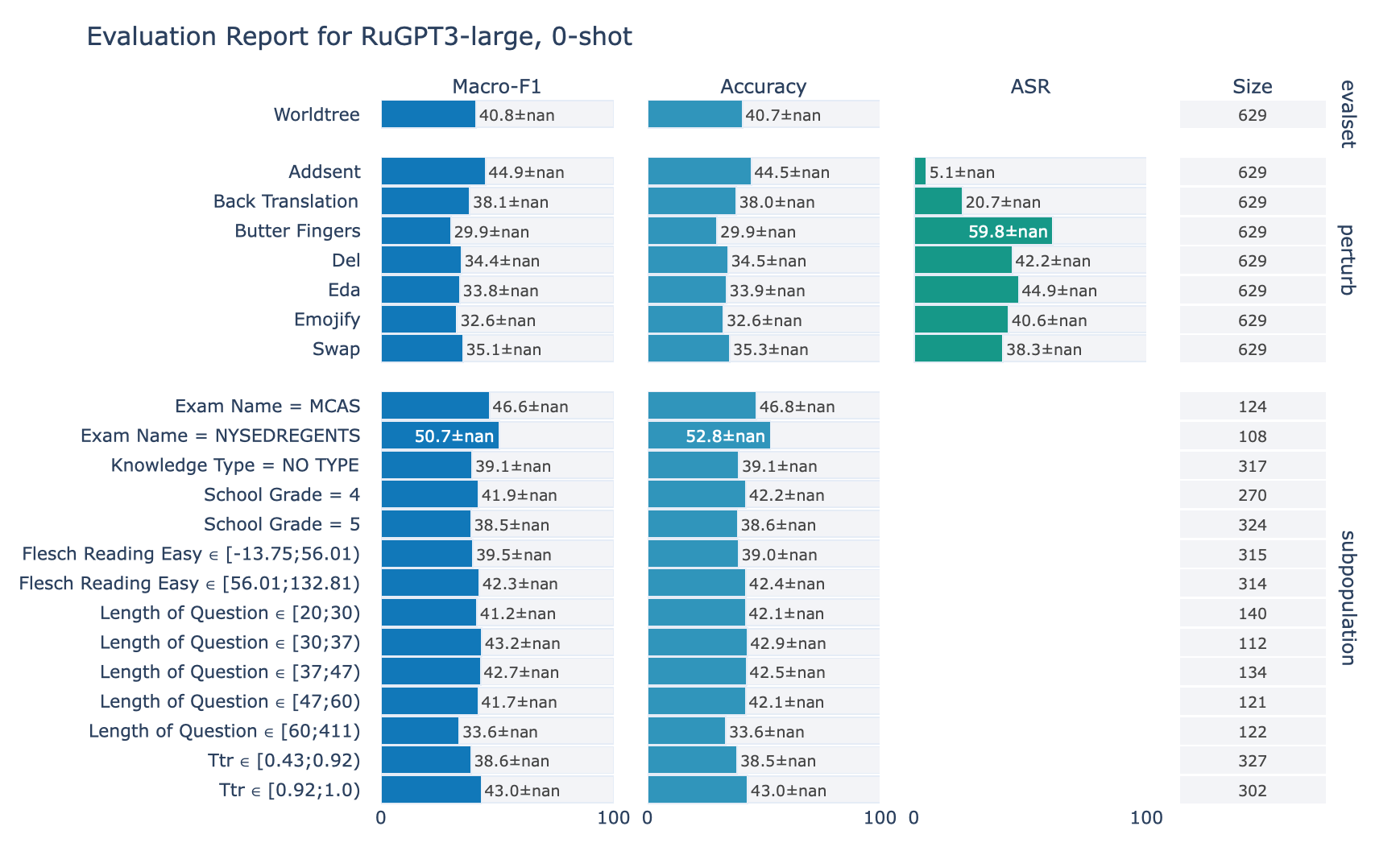
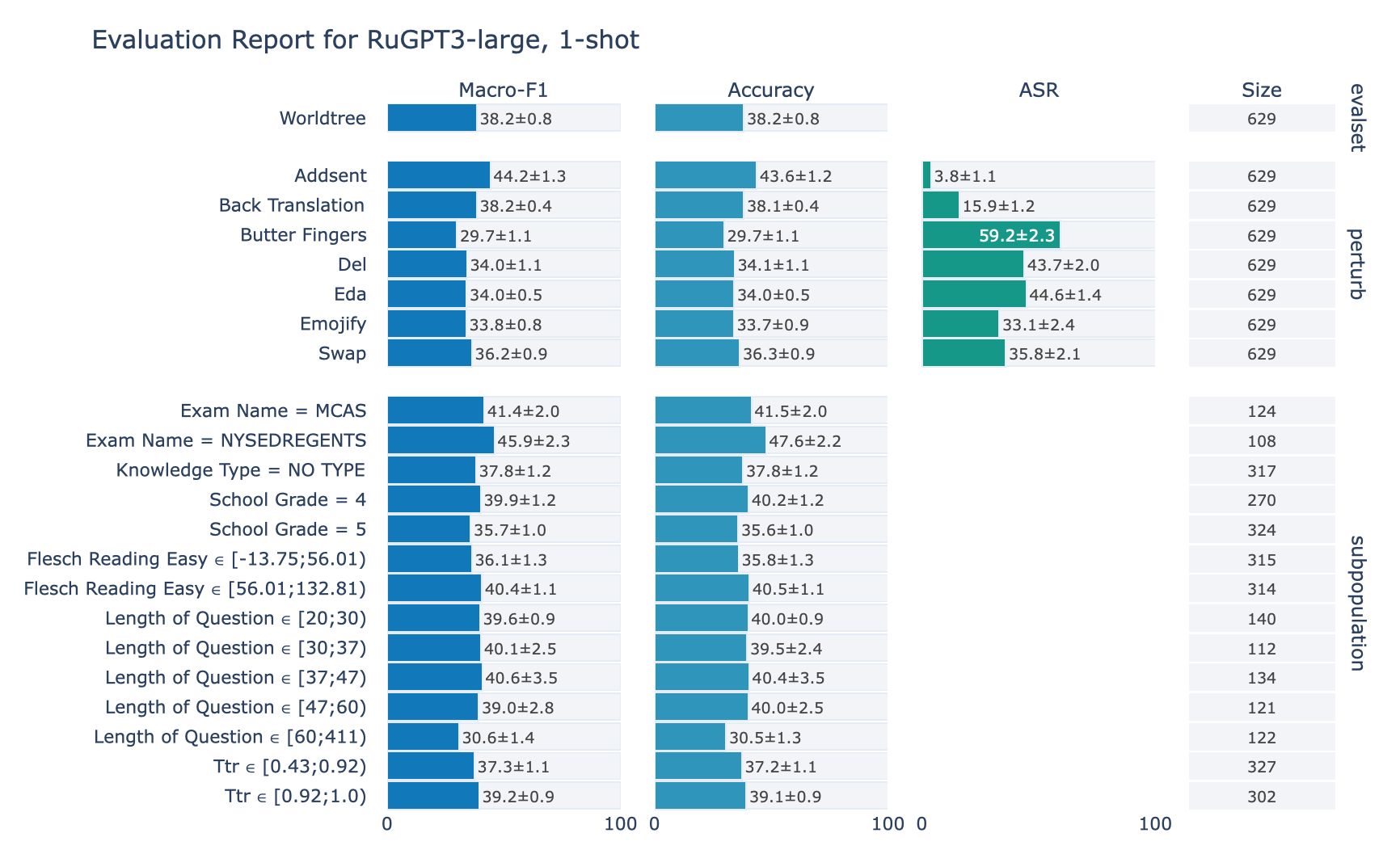
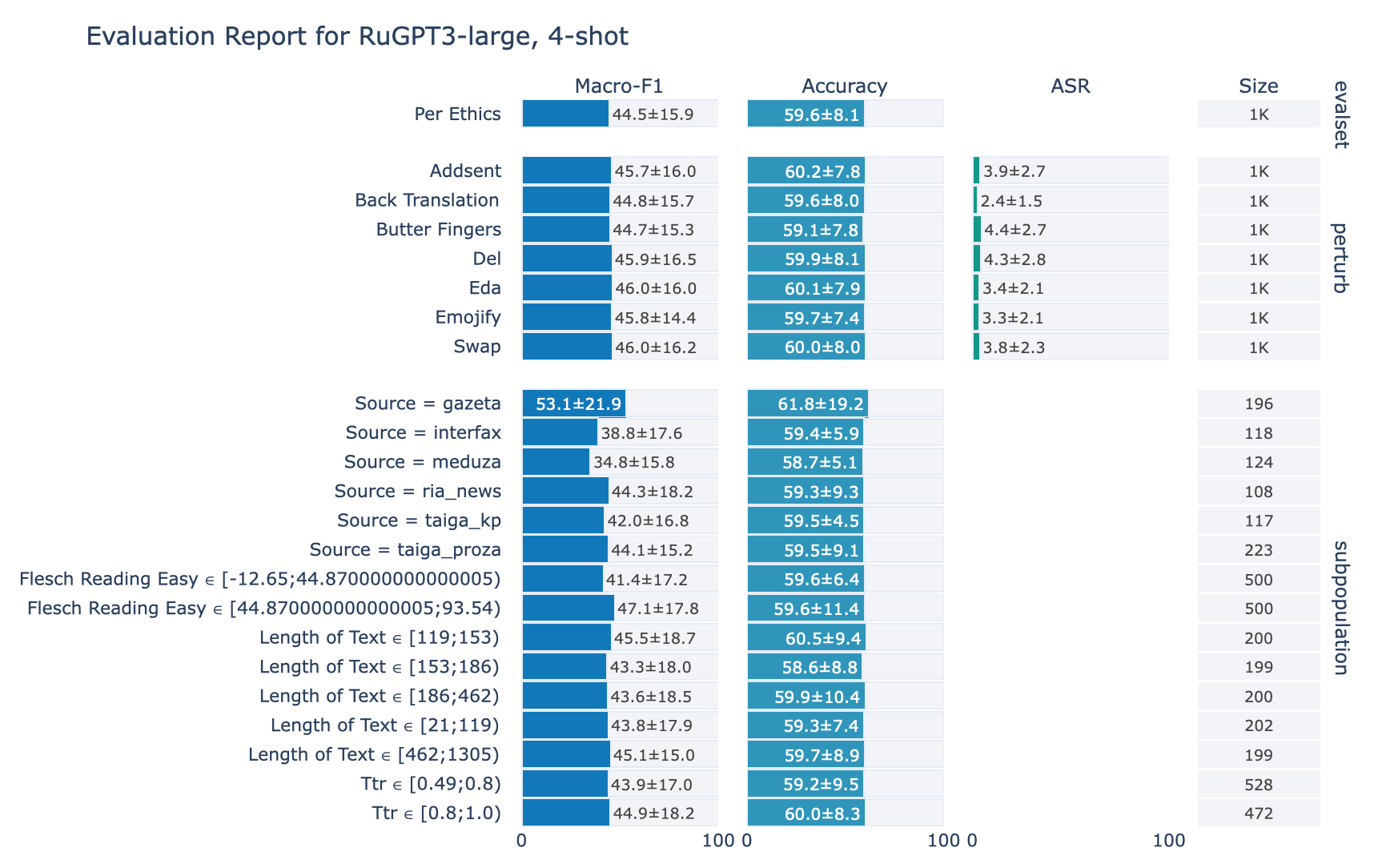
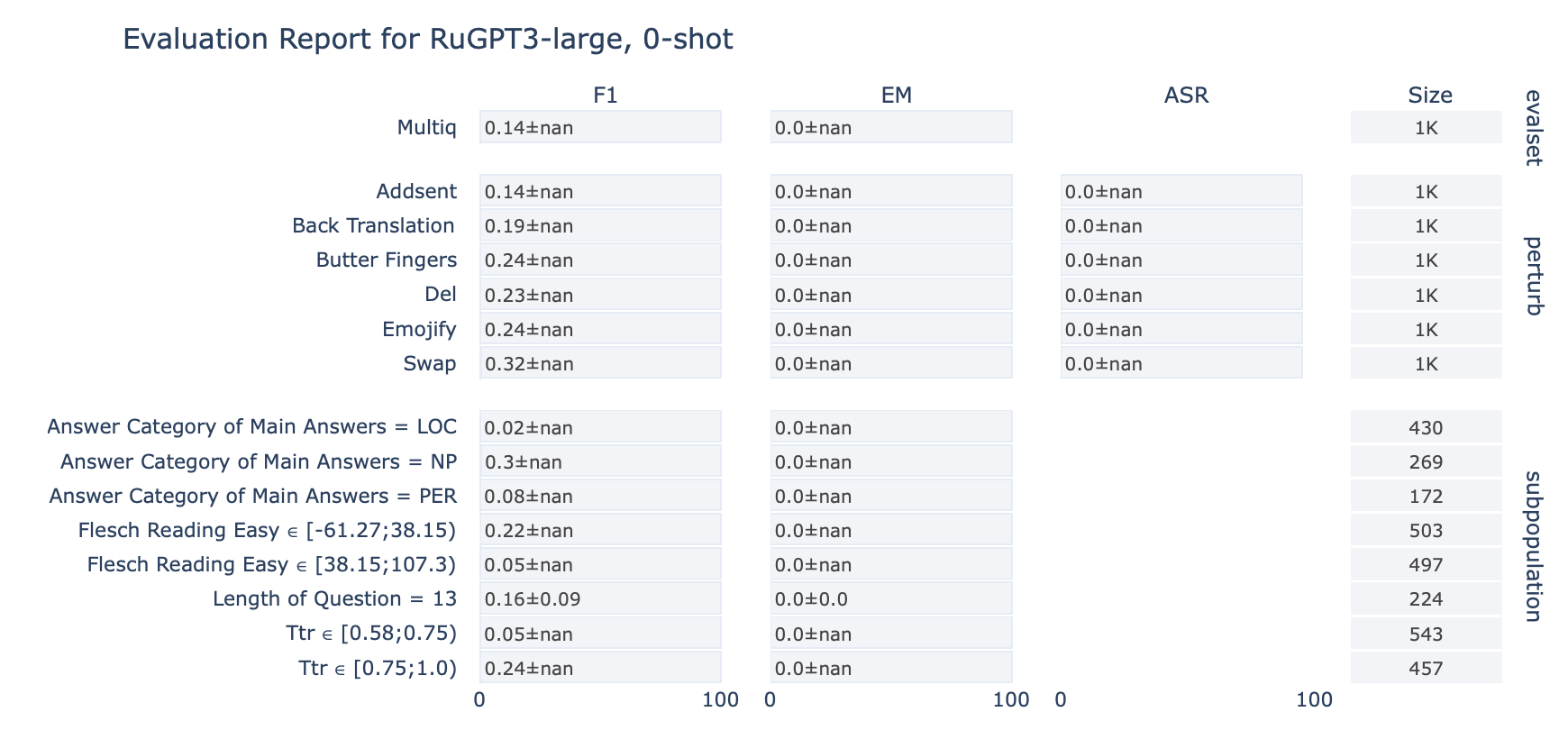
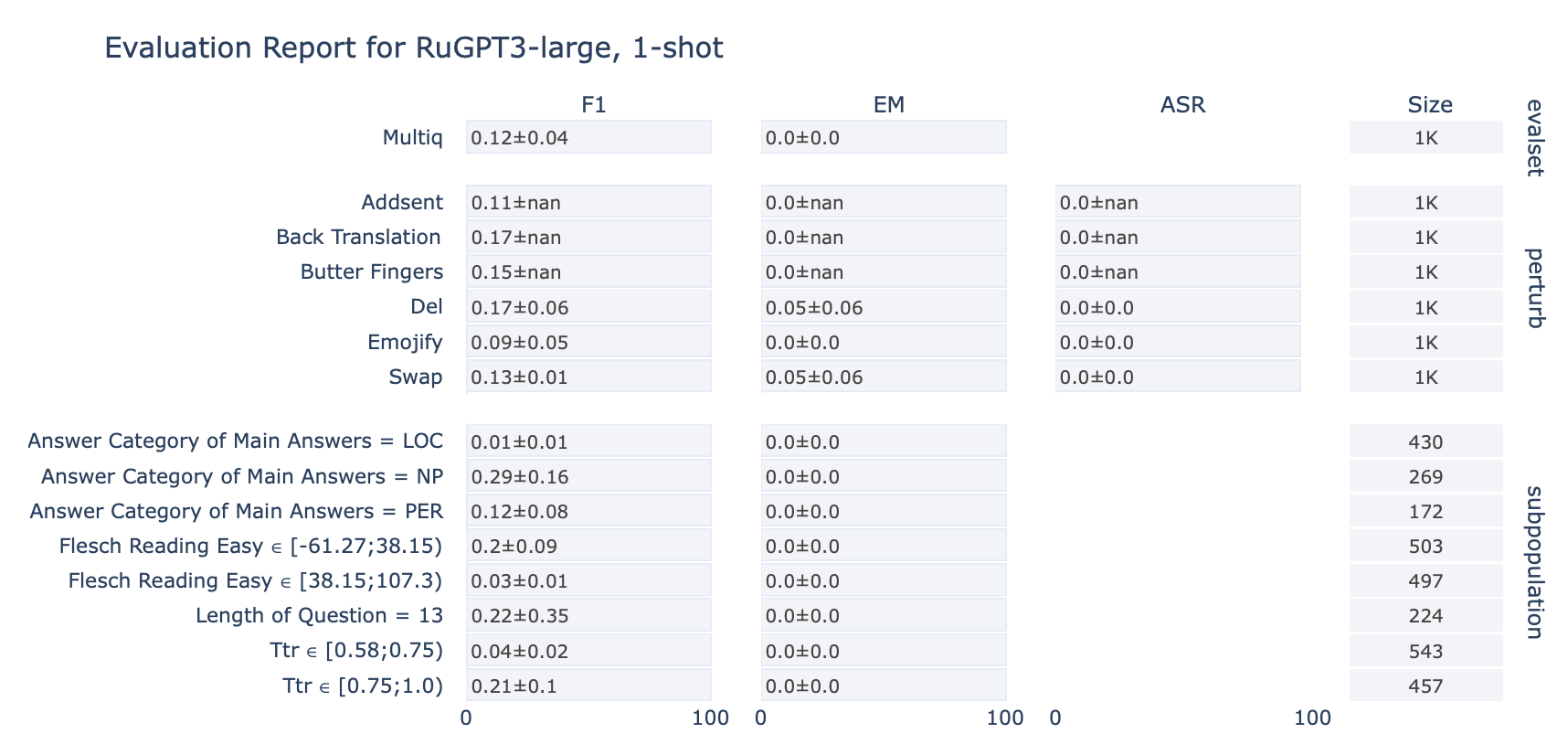
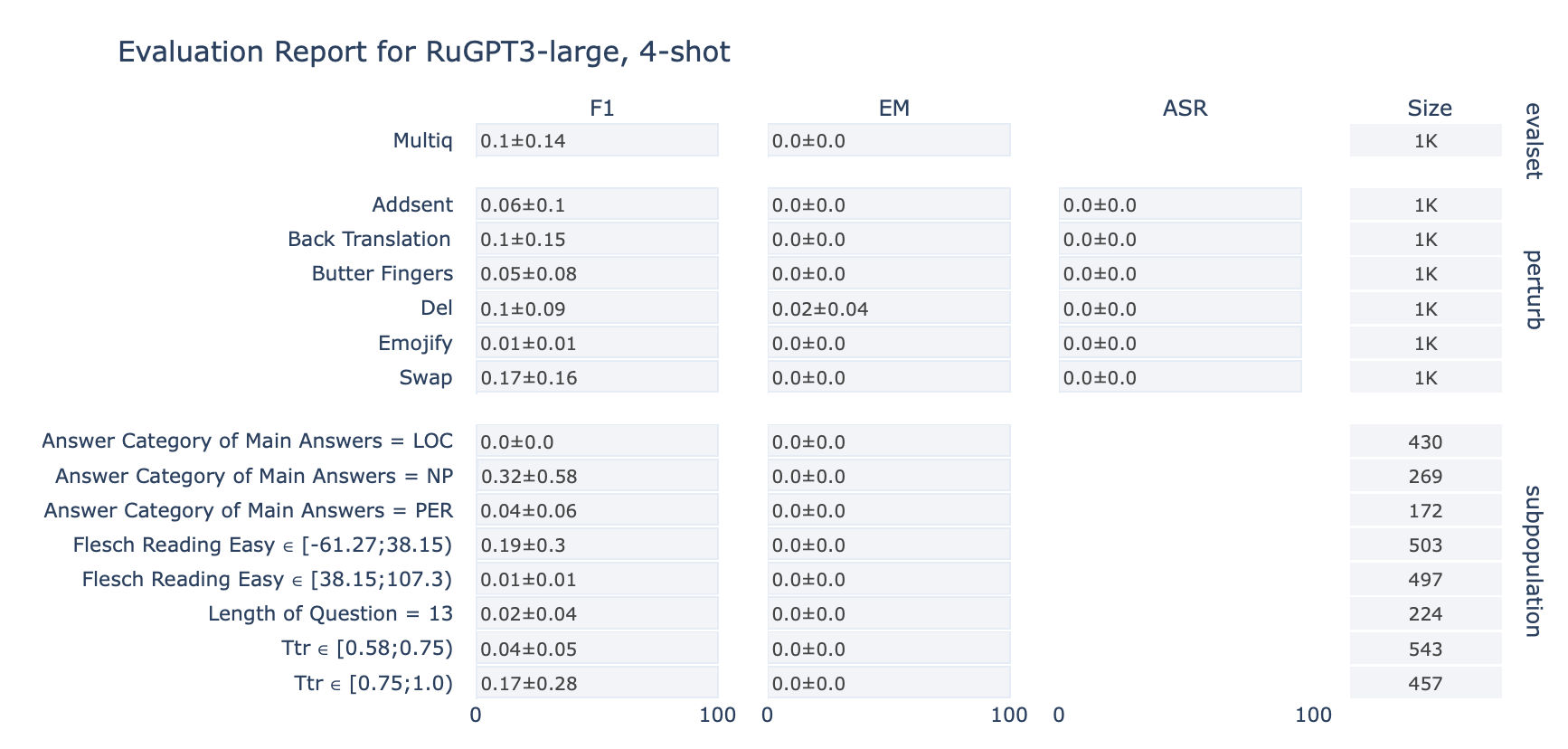
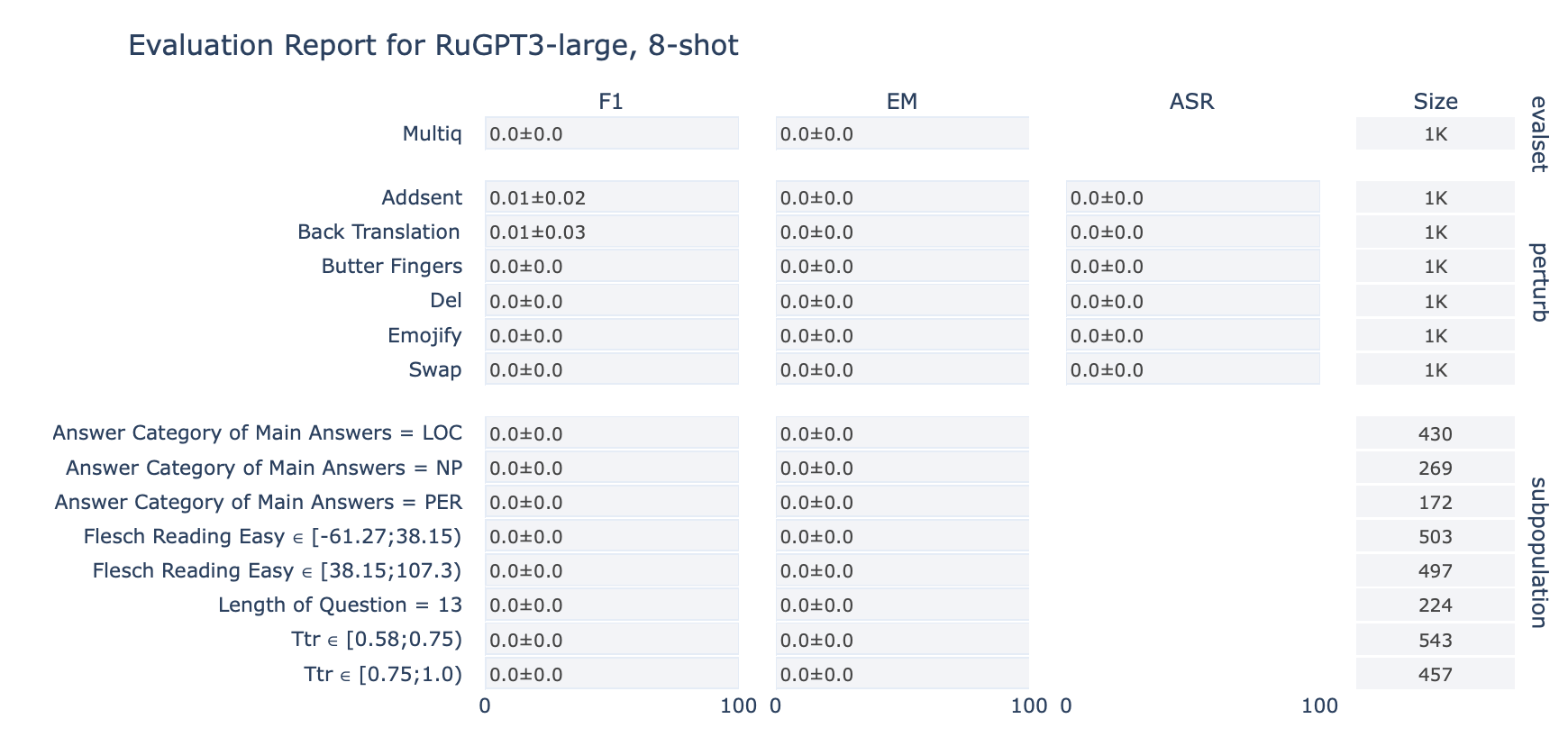
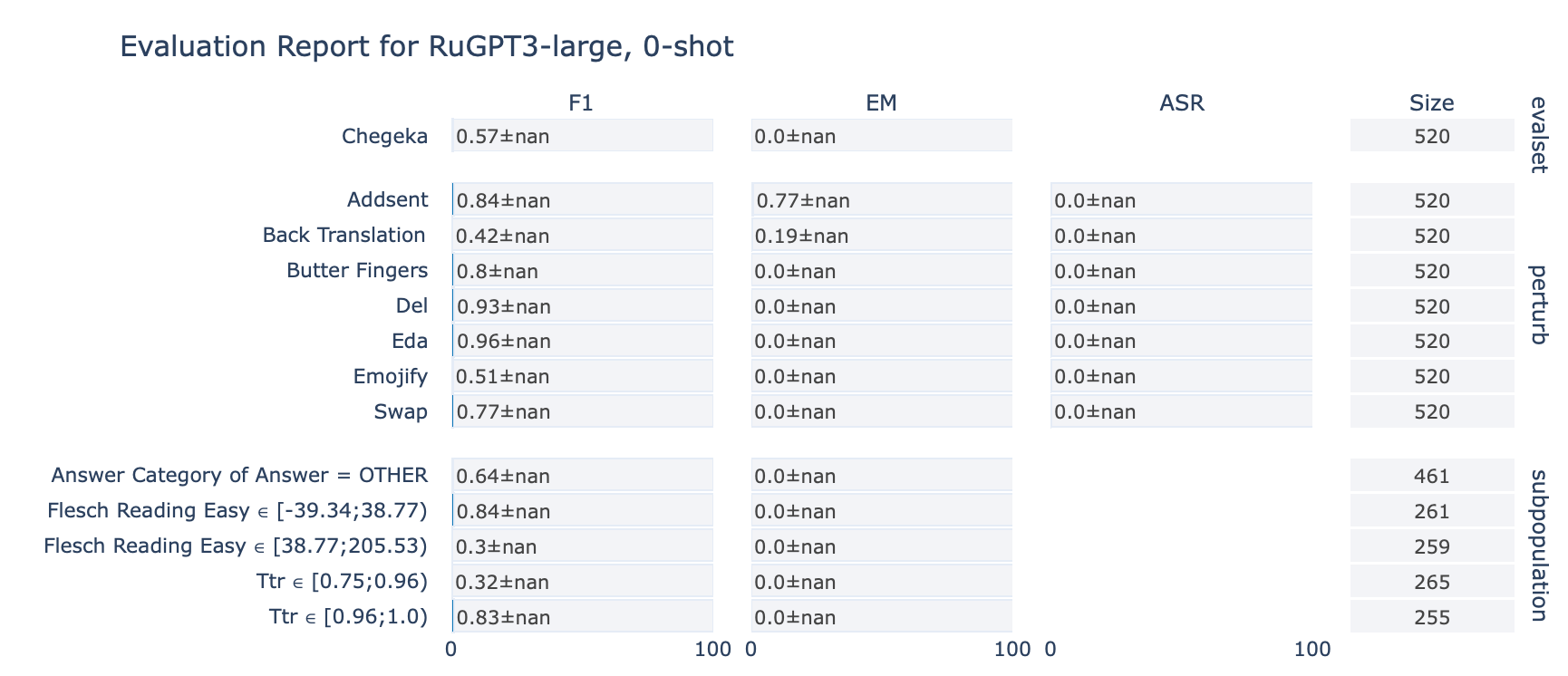
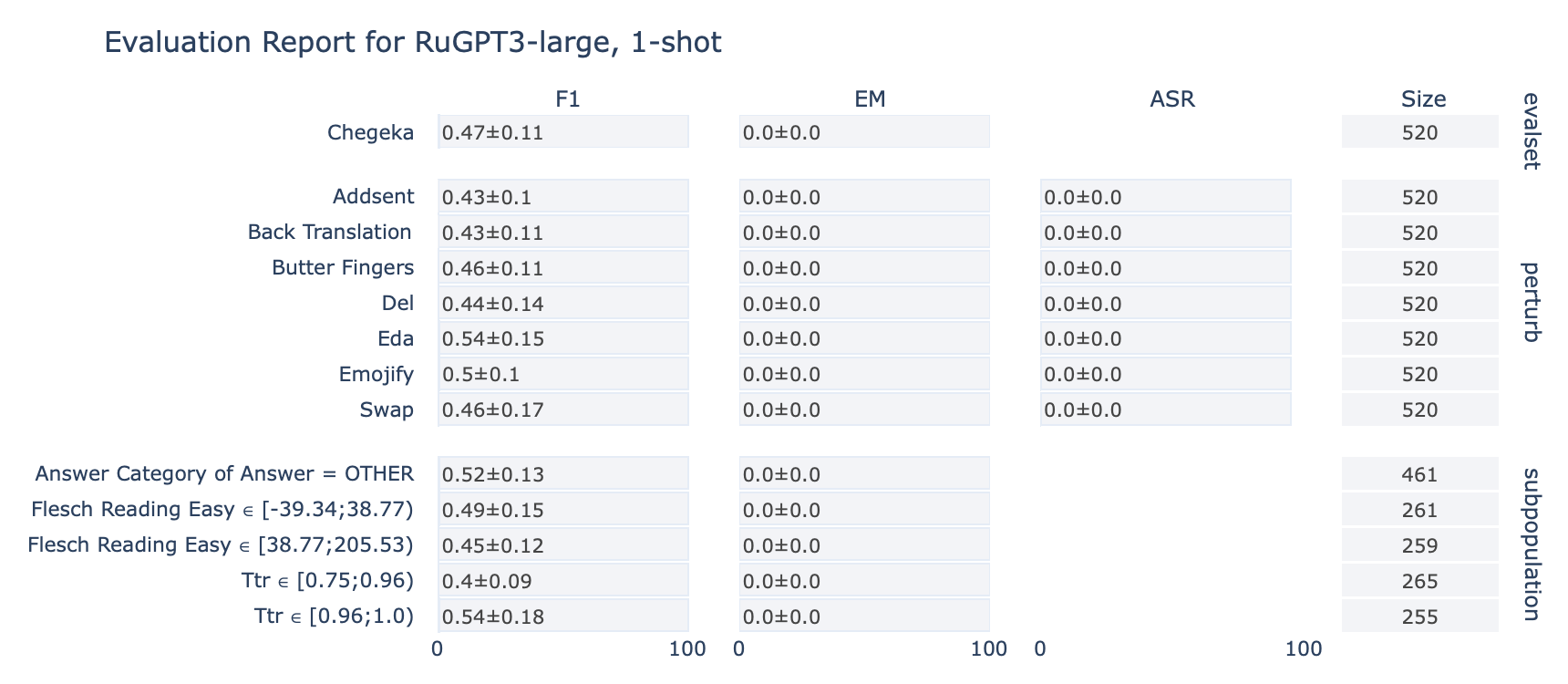
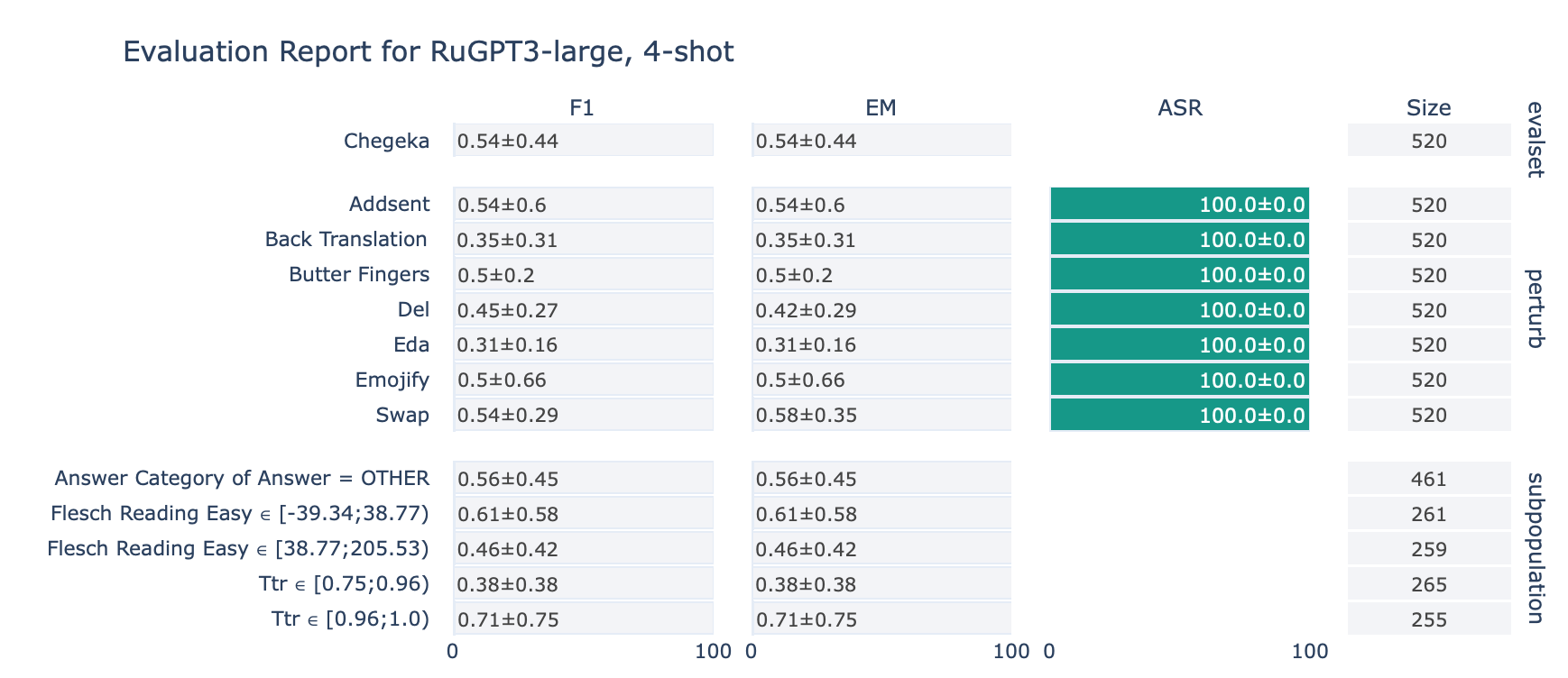
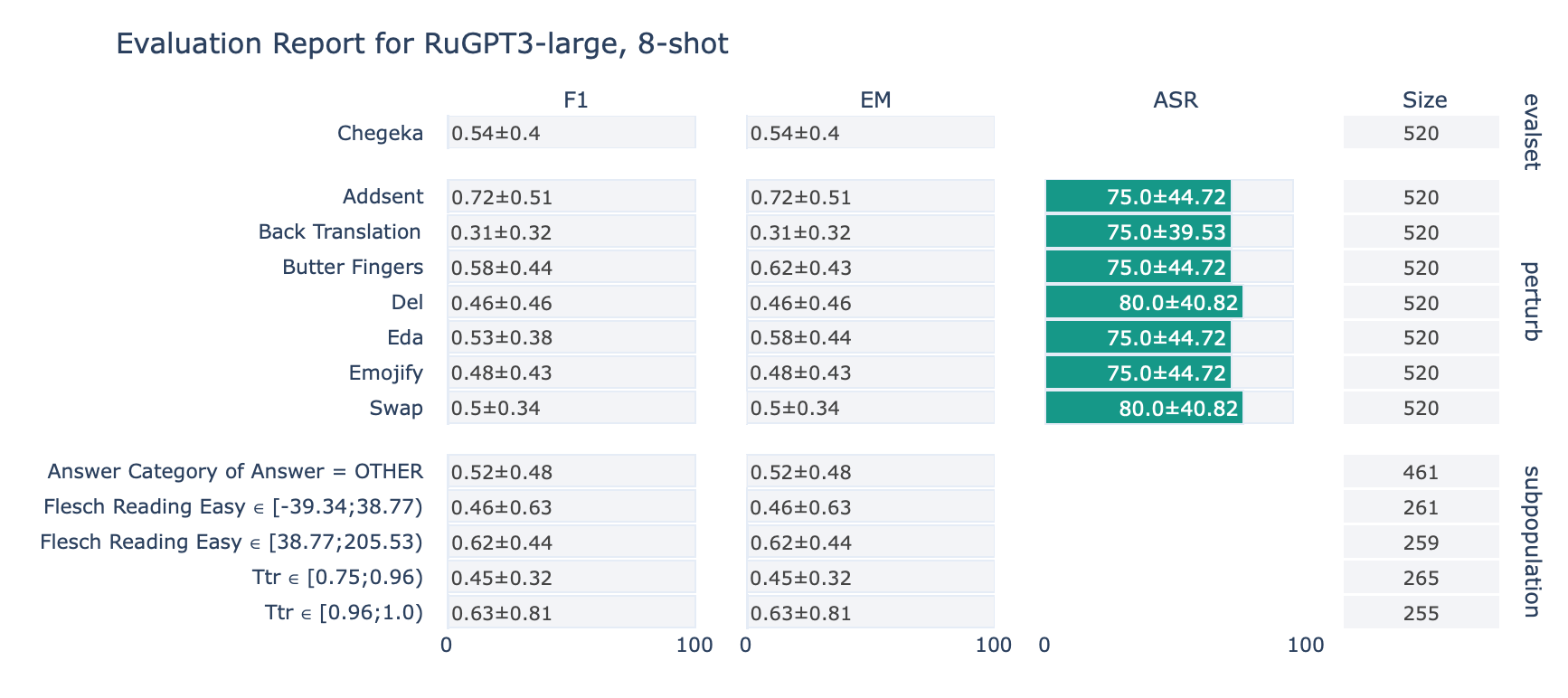
ruGPT-3 Large
Winograd
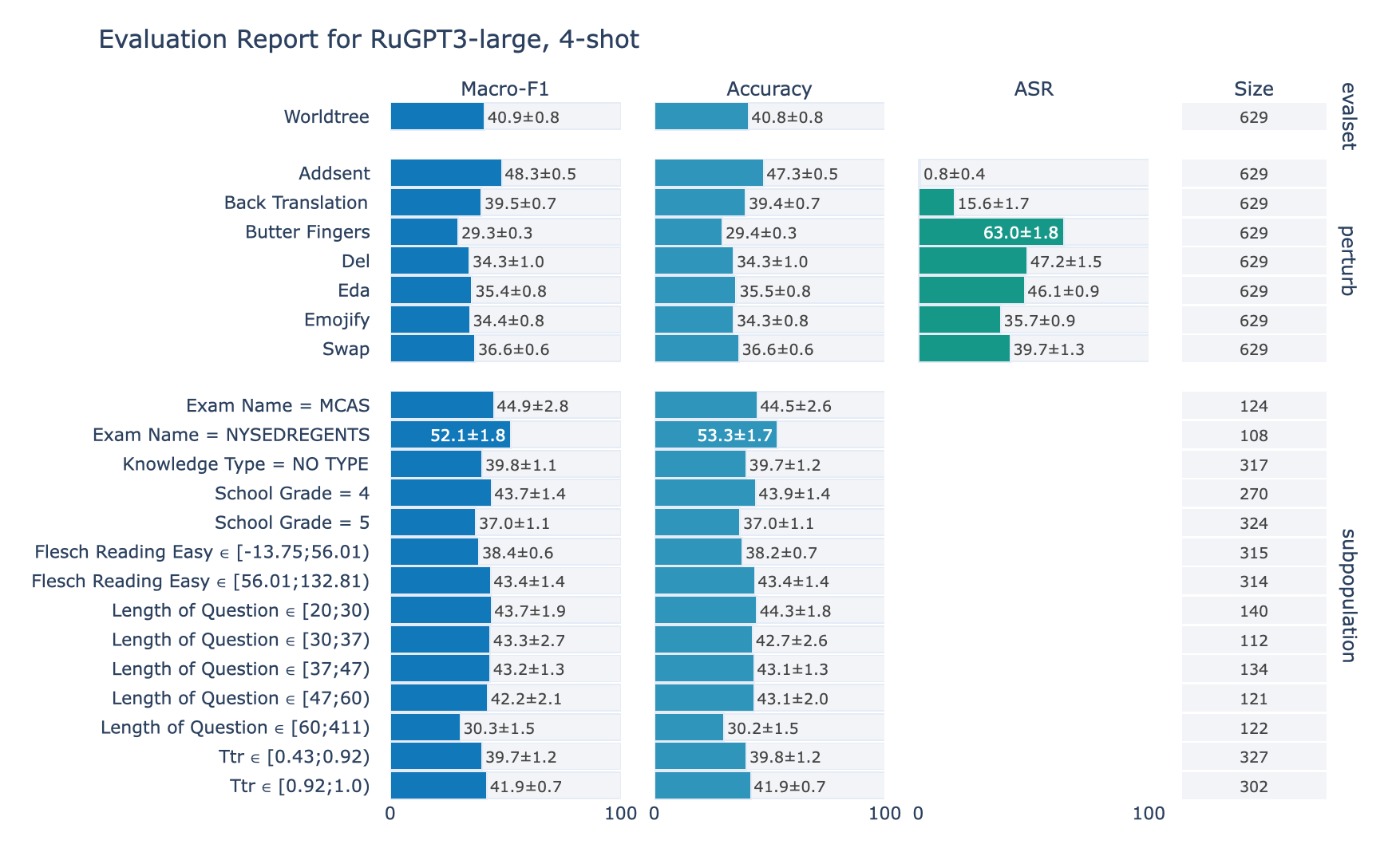
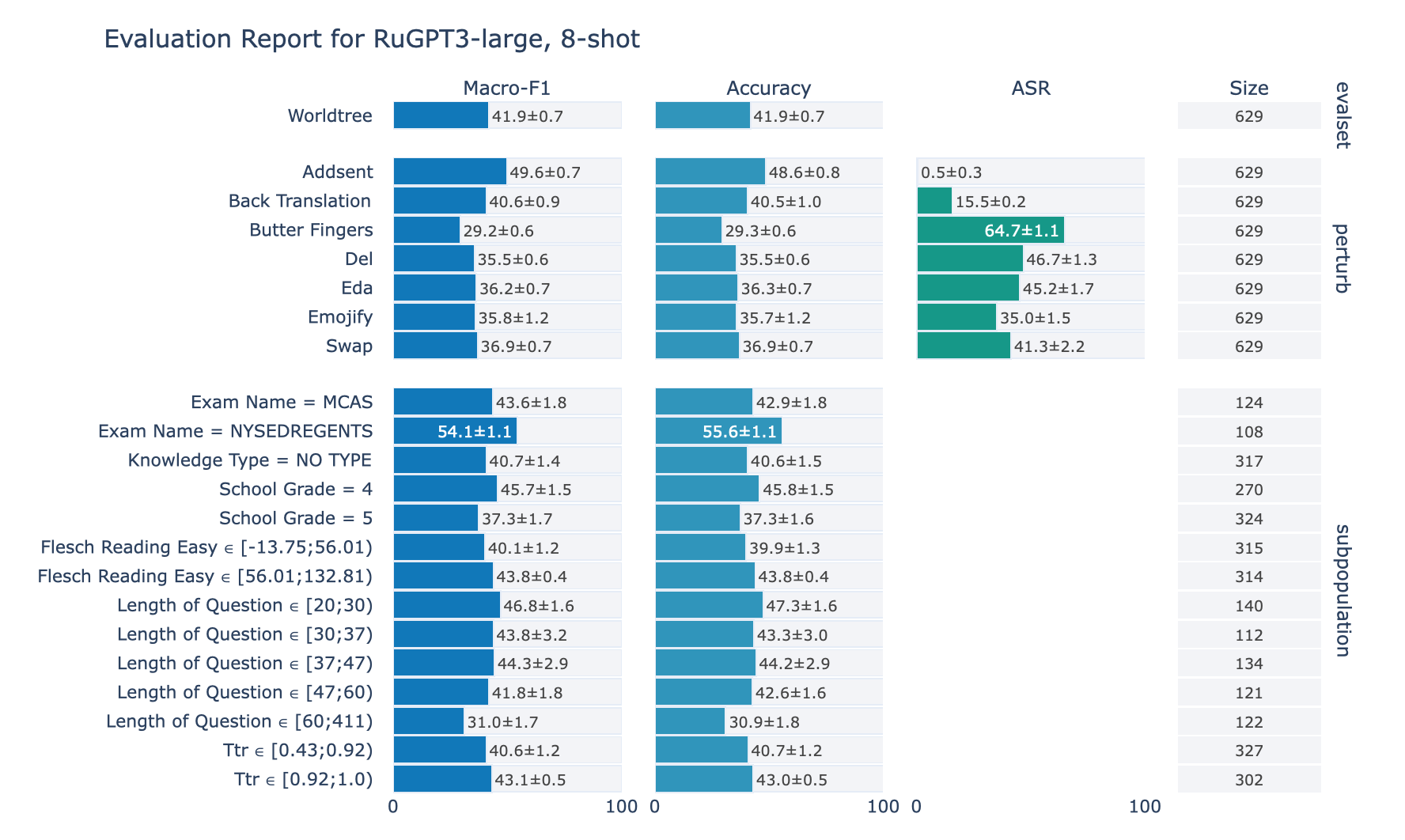
RuWorldTree
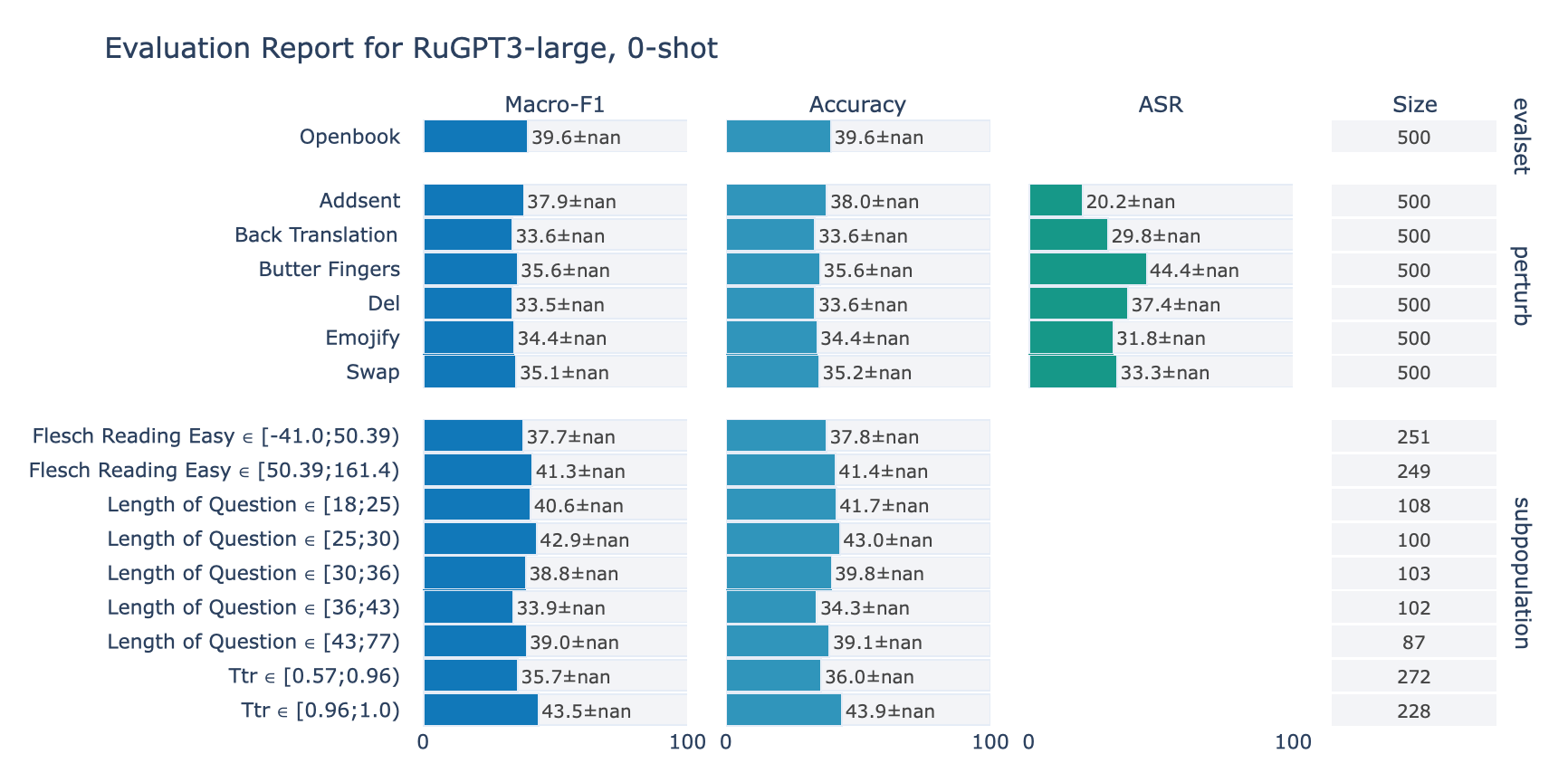
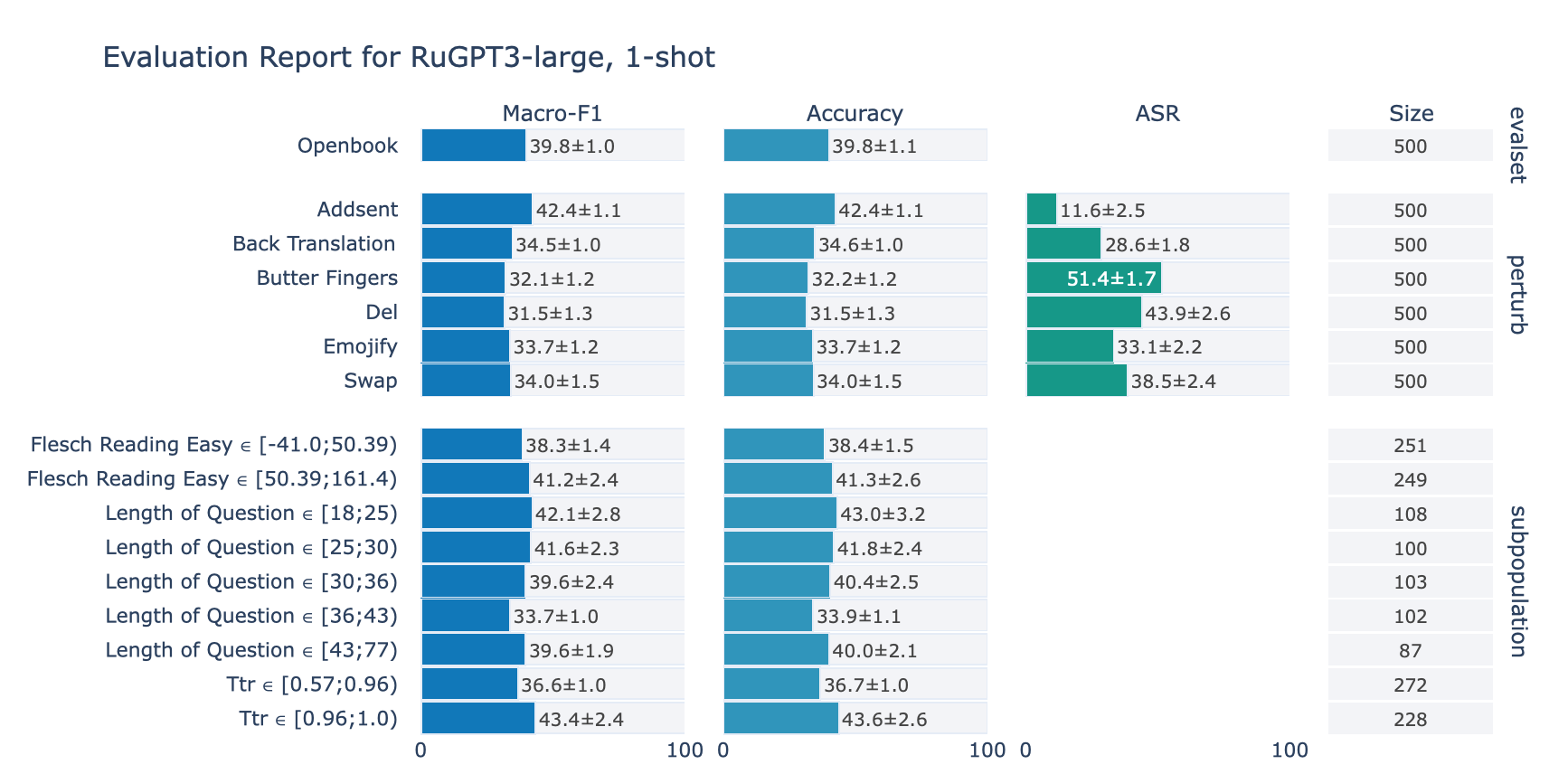
RuOpenBookQA
Ethics
1
Ethics
2
MultiQ
CheGeKa