About TAPE
Assessing Few-shot Russian Language Understanding.
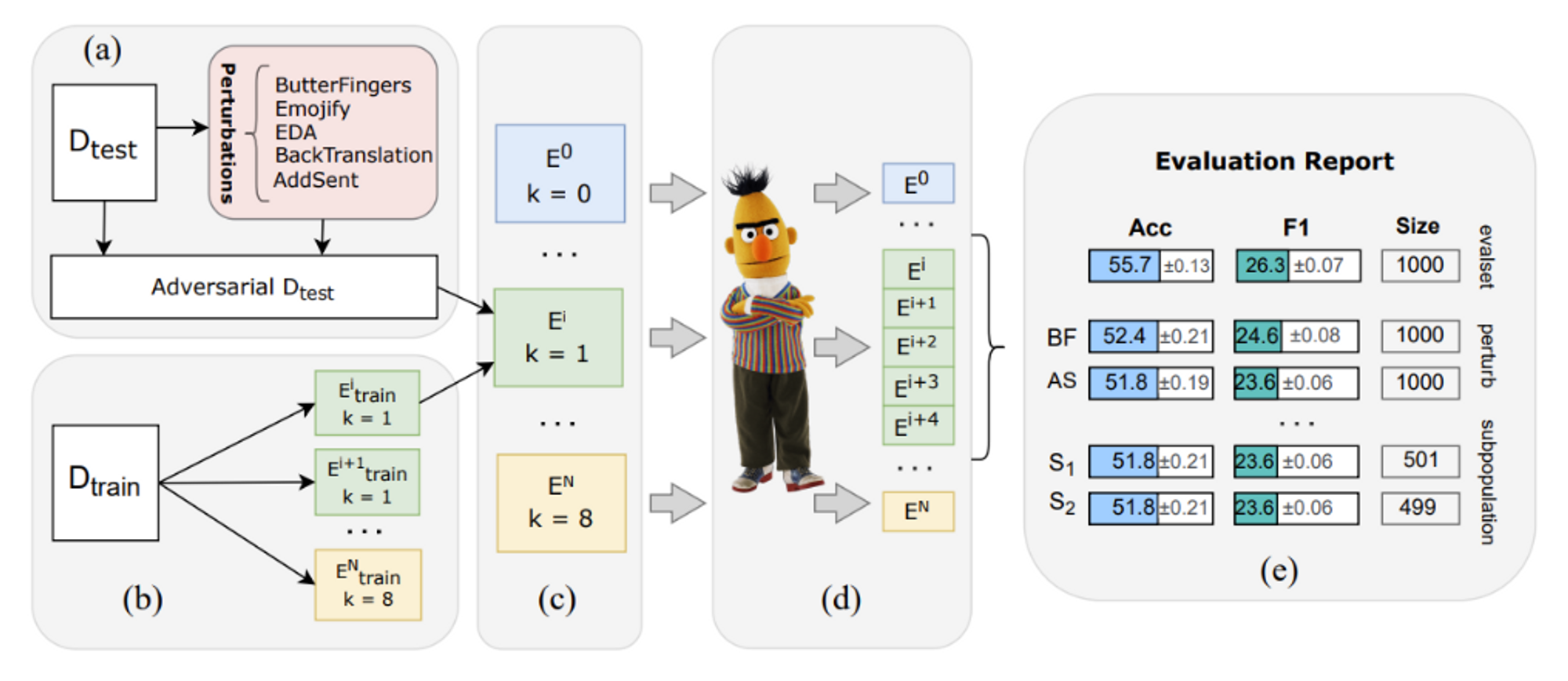
TAPE (Text Attack and Perturbation Evaluation) is a novel benchmark for few-shot Russian language understanding evaluation that includes six complex NLU tasks, covering multi-hop reasoning, ethical concepts, logic and commonsense knowledge. TAPE's design focuses on systematic zero-shot and few-shot NLU evaluation across different axes:
- subpopulations for nuanced interpretation
- linguistic-oriented adversarial attacks and perturbations for analysing robustness.
General data collection principles of TAPE are based on combining "intellectual abilities" needed to solve GLUE-like tasks, ranging from world knowledge to logic and commonsense reasoning. Based on the GLUE format, we have built six new datasets from the ground up, each of them requiring the modeling abilities of at least two skills:
- Logical reasoning (Winograd scheme)
- Reasoning with world knowledge (RuOpenBookQA, RuWorldTree, MultiQ, and CheGeKa)
- Multi-hop reasoning (MultiQ)
- Ethical judgments and reasoning (Ethics)